27 Jan 2025
@Transactional 메서드 안에서의 lock이 정상작동 하지 않은 경우가 있어서 조사해보았다.
예제 코드
테스트 엔티티에 1000개의 quantity를 가지고 있는 테이블 로우가 있다.
API에 요청을 하면 이 quantity의 기존 값에 -1 이 된다.
값이 0이면 아무것도 하지 않는다.
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@Service
@RequiredArgsConstructor
public class TestService {
private final TestRepository testRepository;
private static final Long TEST_ID = 1L;
@Transactional
public void execute() {
TestEntity entity = testRepository.findById(TEST_ID)
.orElseThrow(RuntimeException::new);
if (entity.getQuantity() == 0) return;
entity.consume();
}
}
1000명의 유저가 동시에 이 API에 요청을 하면 어떻게 될까?
postman pre-request 기능을 이용해서 요청해보자.
// 요청을 보내는 함수 정의
const sendRequest = async (i) => {
const url = 'http://localhost:8080/test'; // API 엔드포인트
const method = 'POST'; // HTTP 메서드
const headers = {
'Content-Type': 'application/json'
};
// 요청 옵션 설정
const requestOptions = {
url: url,
method: method,
header: headers,
};
// 요청 보내기
try {
const response = await pm.sendRequest(requestOptions);
console.log(`Request ${i + 1} completed:`, response.json());
} catch (err) {
console.error(`Request ${i + 1} failed:`, err);
}
};
// 1000개의 비동기 요청 보내기
for (let i = 0; i < 1000; i++) {
sendRequest(i); // 비동기로 요청 실행
}
내가 원하는 결과는 1000명이 요청을 하고 수량도 1000개이니 남은 quantity는 0개가 되어야 한다.
하지만 결과는 엉뚱한 값이 나온다. (884개가 나온다.)
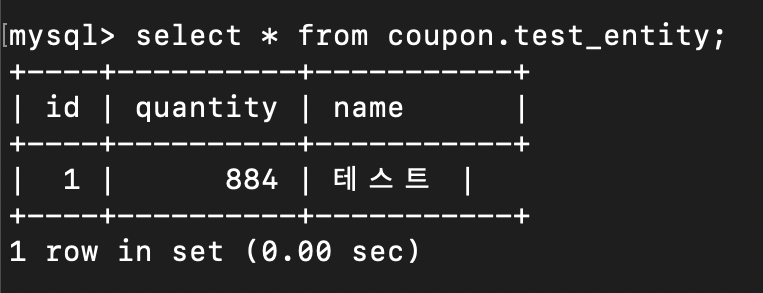
여러 스레드가 하나의 메서드에 접근하여 흔하게 생기는 동시성 문제가 생긴 것이다.
그렇기에 해당 메서드에 lock을 걸어 제어를 해보자.
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
@Service
@RequiredArgsConstructor
public class TestService {
private final TestRepository testRepository;
private static final Long TEST_ID = 1L;
private final Lock lock = new ReentrantLock(true);
@Transactional
public void execute() {
lock.lock();
try {
TestEntity entity = testRepository.findById(TEST_ID)
.orElseThrow(RuntimeException::new);
if (entity.getQuantity() == 0) return;
entity.consume();
} finally {
lock.unlock();
}
}
}
임계 영역에 lock을 걸고 로직이 끝나면 lock도 반납한다.
그리고 ReentrantLock에 공정모드도 설정했으니, 순서대로 요청이 될 것이다.
임계 영역을 잘 제어했으니, 결과가 0이 나와야 할 것이다.
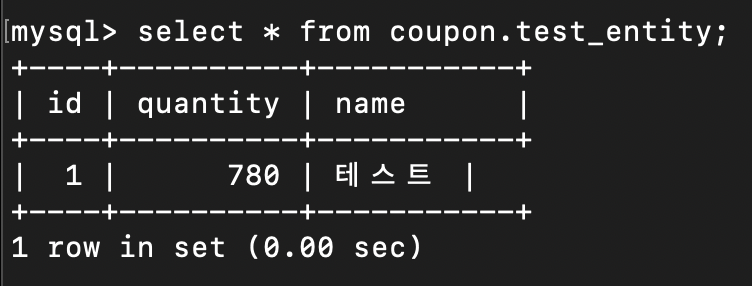
결과가 예상과 달리 780이 나왔다. 왜 이럴까?
답은 임계 영역을 잘 제어한 것이 아닌 것이다.
트랜잭션과 lock의 흐름
그림으로 트랜잭션과 lock의 흐름을 알아보자.
먼저 lock을 적용하기 전의 메서드의 흐름이다.
유저가 request를 하면 트랜잭션이 적용된 메서드가 실행이 되고 그 안에서 엔티티 조회, 변경감지를 이용한 엔티티 수정이 이루어진다.
로직이 전부 실행되고 메서드가 끝나고 난 뒤 트랜잭션은 커밋이 되어 해당 내용이 DB에 저장된다.
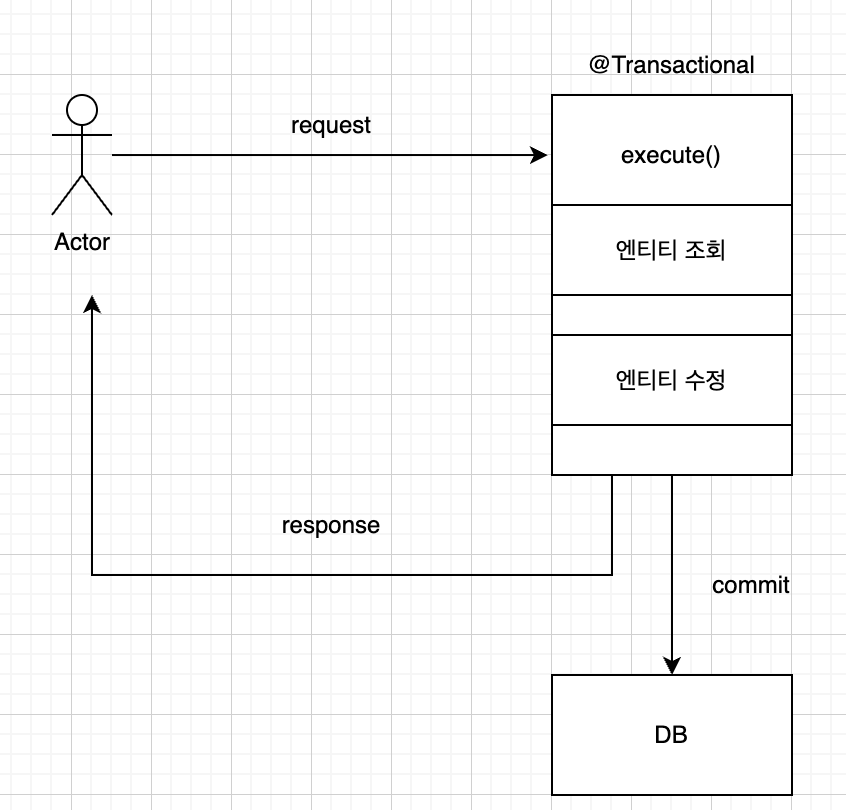
여기서 락을 적용을 하면 엔티티 조회, 엔티티 수정 단계를 잠가서 다른 스레드가 접근하지 못하게 막는다.
하지만 락이 해제되고 트랜잭션이 커밋되기 전의 잠깐의 순간에 다른 스레드가 접근할 수 있는 것이다.
즉, 트랜잭션 범위와 락의 범위가 맞지 않는 것이다. 결국 임계 영역을 잘못 설정한 것이다.
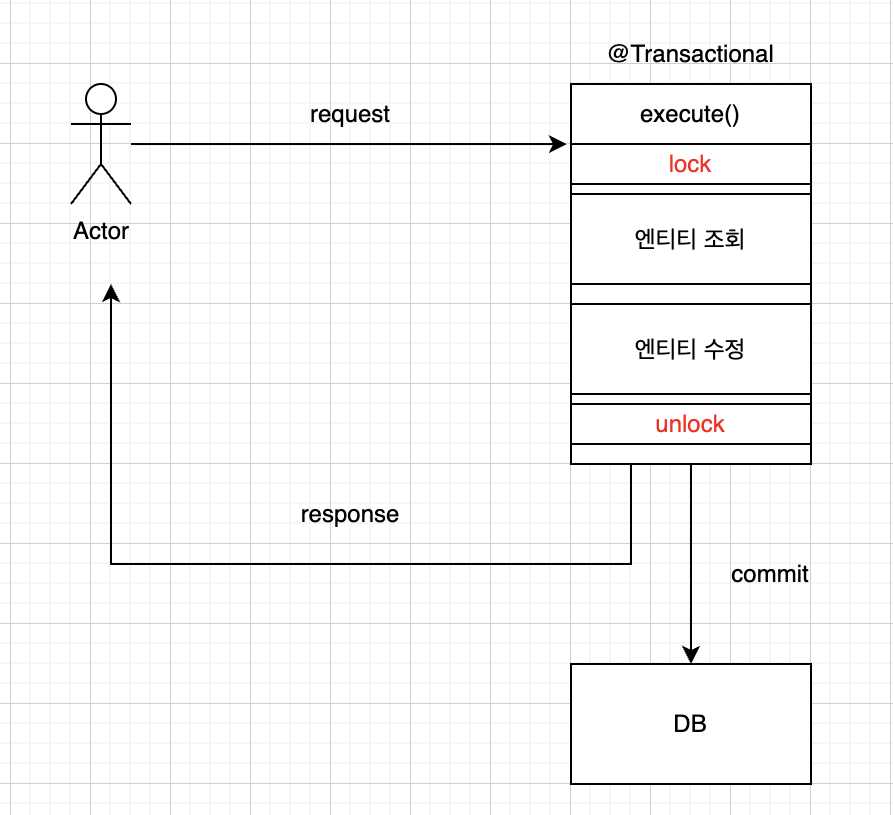
이것을 수정하려면 트랜잭션 시작과 종료를 lock으로 감싸야 한다.
기존 : 트랜잭션 시작 → lock 획득 → 엔티티 조회 → 엔티티 수정 → lock 반납 → 트랜잭션 커밋/종료
수정 : lock 획득 → 트랜잭션 시작 → 엔티티 조회 → 엔티티 수정 → 트랜잭션 커밋/종료 → lock 반납
이렇게 수정을 한다면 해당 메서드의 모든 작업이 하나의 스레드만 들어올 수 있게 되어, 동시성 문제가 해결될 것이다.
주의할 점은 트랜잭션을 호출할 때 다른 클래스에서 호출해야 트랜잭션이 적용된다.
트랜잭션 AOP는 프록시 기반으로 동작한다.
같은 클래스 내부에서 한 메서드가 다른 메서드를 호출하는 경우 프록시를 거치지 않고 직접 호출되기 때문에 트랜잭션이 적용되지 않는다.
여기서는 static 클래스로 간단하게 만들었다.
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Component;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
@Service
@RequiredArgsConstructor
public class TestService {
private final TestRepository testRepository;
private static final Long TEST_ID = 1L;
@Component
@RequiredArgsConstructor
static class ExecuteProxy {
private final TestService testService;
private final Lock lock = new ReentrantLock(true);
public void execute() {
lock.lock();
try {
testService.process();
} finally {
lock.unlock();
}
}
}
@Transactional
public void process() {
TestEntity entity = testRepository.findById(TEST_ID)
.orElseThrow(RuntimeException::new);
if (entity.getQuantity() == 0) return;
entity.consume();
}
}
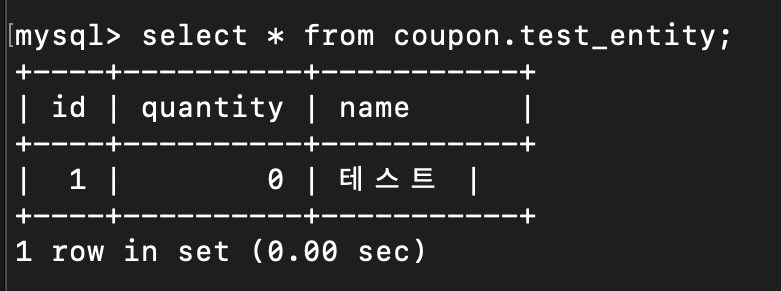
원하는 결과가 잘 나온 것을 볼 수 있다.
20 Jan 2025
패키지 설계의 원칙에 대해서 정리해보자.
패키지 응집도의 원칙
패키지 응집도의 원칙은 개발자가 어떻게 클래스를 패키지에 분류해 넣을지 결정할 때 도움이 된다.
재사용 릴리즈 등가 원칙(REP)
재사용 릴리즈 등가 원칙은 말 그대로 재사용 단위와 릴리즈 단위가 같다는 원칙이다.
어떤 프로그램을 사용하는 사용자 입장에서는 프로그램을 작성한 사람에게 재사용할 수 있도록 유지보수해주길 바란다.
재사용자들이 요구하는 것을 충족시키려면 작성자는 반드시 자신의 소프트웨어를 재사용 가능한 패키지로 조직한 다음 릴리즈 번호를 붙이고 계속 추적해야 한다.
패키지의 모든 클래스가 재사용 가능하든지, 모두 그렇지 않든지 해야 한다.
또한 재사용자가 누구인지도 고려해야 한다.
패키지 안의 모든 클래스는 동일한 재사용자를 대상으로 해야 한다.
공통 재사용 원칙(CRP)
공통 재사용 원칙은 패키지 안의 클래스들은 함께 재사용 되어야 한다는 원칙이다.
공통 재사용 원칙은 어떤 클래스들이 패키지에 포함되어야 하는지 결정할 때 도움이 된다.
단독으로 재사용되는 클래스는 거의 없다.
대부분의 경우, 재사용 가능한 클래스들은 재사용 가능에 대해 같은 추상적 범주에 속해 있는 다른 클래스들과 협력한다.
공통 폐쇄 원칙(CCP)
공통 폐쇄 원칙은 같은 패키지 안의 클래스들은 동일한 종류의 변화에는 모두 폐쇄적이어야 한다는 원칙이다.
패키지에 어떤 변화가 영향을 미친다면, 그 변화는 그 패키지의 모든 클래스에 영향을 미쳐야 하고 다른 패키지에는 영향을 미치지 않아야 한다.
패키지 결합도의 원칙
의존 관계 비순환 원칙(ADP)
의존 관계 비순환 원칙은 패키지 의존성 그래프에서 순환을 허용하지 말라는 규칙이다.
누군가가 의존하는 것을 변경 했을 때 되던 것이 안 되는 경우 의존 관계 순환을 없애면 이 문제를 해결 가능하다.
개발 환경을 릴리즈로 만들 수 있는 패키지로 분할하는 것이다.
안정된 의존 관계 원칙(SDP)
안정된 의존 관계 원칙이란 의존은 안정적인 쪽으로 향해야 한다는 원칙이다.
안정성이란 변화와는 크게 관련이 없고 쉽게 움직이지 않는다면 안정성이 있다고 한다.
안정된 의존 관계 원칙을 사용해서 특정 변화에 쉽게 반응할 수 있는 패키지를 만든다.
쉽게 바뀔 것이라고 예상되는 패키지들이 바뀌기 어려운 패키지들의 의존 대상이 되어서는 안 된다.
안정성 측정 방법
패키지에 들어오거나 나가는 의존 관계 화살표의 수를 세는 것으로 패키지의 안정성을 측정할 수 있다.
들어오는 결합 Ca, 나가는 결합 Ce, 불안정성 I
\[I = Ce / (Ca + Ce)\]
I의 측정값이 1이면, 그 패키지에 의존하는 다른 패키지가 없다는 뜻이며, 동시에 이 패키지가 의존하는 패키지가 있다는 뜻이다. 이 패키지는 최고로 불안정한데, 책임을 지지 않으며 동시에 의존적이다.
I의 측정감이 0이면, 다른 패키지들은 그 패키지에 의존하지만 자기 자신은 다른 패키지에 의존하지 않는다는 뜻이다. 이 패키지는 책임을 지며 또 독립적이다.
SDP에 따르면 어떤 패키지의 I 측정값은 그 패키지가 의존하는 다른 패키지들의 I 값들보다 반드시 커야 한다.
즉, 의존 관계의 방향으로 I 측정값이 줄어들어야 한다.
모든 패키지가 안정적일 필요는 없다. 어떤 패키지는 불안정하고 또 어떤 패키지는 안정적인 설계가 좋은 설계다.
안정된 추상화의 원칙
안정된 추상화의 원칙은 패키지가 자신이 안정적인 만큼 추상적이기도 해야 한다는 원칙이다.
안정된 추상화 원칙에 따르면 안정적인 패키지는 그 안정성 때문에 확장이 불가능하지 않도록 추상적이기도 해야 한다.
거꾸로, 이 원칙에 따르면 불안정한 패키지는 구체적이어야 하는데, 그 불안정성이 그 패키지 안의 구체적인 코드가 쉽게 변경될 수 있도록 허용하기 때문이다.
따라서 어떤 패키지가 안정적이라면 확장할 수 있도록 추상 클래스들로 구성되어야 한다.
추상성 측정법
- Nc : 패키지 안에 들어 있는 클래스 수
- Na : 패키지 안에 들어 있는 추상 클래스 수.
- A: 추상성(0~1)
\[A = Na / Nc\]
0은 패키지에 추상 클래스가 하나도 없다는 뜻이고, 1은 이 패키지에 추상 클래스밖에 들어 있지 않다는 뜻이다.
(0,0) 주변 영역은 고통의 지역이라고 불리는 배제할 지역이고, (1,1) 주변 영영은 쓸모없는 지역이라고 불린다.
(1,0)과 (0,1)을 잇는 직선을 주계열이라고 한다.
주계열 위에 있는 패키지는 안정성에 비해 너무 추상적이지도 않고, 추상성에 비해 너무 불안정하지도 않다.
13 Jan 2025
이번에 장애 대응 프로세스를 구축하면서 Docker API에서 받은 데이터를 클라이언트로 실시간 전송하는 코드를 구현하게 되었다.
클라이언트로 데이터를 전송하는 기술 중 SSE, Polling, WebSocket 중 어떤 것을 사용하는 것이 적절할지 비교해보았다.
SSE란?
SSE(Server Sent Events)는 서버가 클라이언트에 실시간으로 이벤트를 푸시할 수 있는 기술이다.
클라이언트는 EventSource 객체를 사용해서 서버로부터 실시간으로 데이터를 받는다.
HTTP 프로토콜을 기반으로 하며, 서버에서 클라이언트로만 데이터가 흐른다.
장단점
장점
- 단방향 실시간 통신이 적합하다. (서버 → 클라이언트)
- 연결이 유지되므로 서버에서 데이터를 실시간으로 푸시할 수 있다.
단점
- 양방향 통신을 지원하지 않는다.
- 일부 오래된 브라우저에서 지원되지 않는다.
예제 코드
스프링 프레임워크에서 제공하는 SseEmitter 클래스를 사용해서 SSE를 구현한다.
SseEmitter 클래스는 클라이언트가 EventSource 객체를 통해 연결을 유지하고 있는 동안, 클라이언트에게 실시간으로 데이터를 전송한다.
서버가 이벤트를 푸시할 때, 클라이언트와의 연결을 블로킹하지 않고 비동기적으로 데이터를 보낼 수 있다.
주요 메서드
- send() : 클라이언트에게 이벤트 데이터 전송
- complete() : 이벤트 스트리밍이 끝났음을 알림
- completeWithError() : 오류가 발생했을 때 스트리밍을 종료
@RestController
class SSEController {
@GetMapping("/sse")
fun loadSSEServer(): SseEmitter {
val emitter = SseEmitter()
val executorService = Executors.newSingleThreadExecutor()
executorService.submit {
try {
for (i in 0..10) {
val data = SseEmitter.event().name("message").data("Data $i")
emitter.send(data)
Thread.sleep(1000)
}
} catch (e: Exception) {
emitter.completeWithError(e)
}
}
return emitter
}
}
...
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>SSE Example</title>
</head>
<body>
<h1>Server-Sent Events</h1>
<ul id="messages"></ul>
<script>
const eventSource = new EventSource('/sse');
eventSource.onmessage = function(event) {
const li = document.createElement("li");
li.textContent = event.data;
document.getElementById('messages').appendChild(li);
};
</script>
</body>
</html>

1 ~ 10까지의 데이터를 서버에서 클라이언트로 푸시한다.
Polling
Polling은 클라이언트가 주기적으로 서버에 요청을 보내서 데이터를 받는 방식이다.
클라이언트는 일정한 시간 간격으로 서버에 HTTP 요청을 보내고, 서버는 새로운 데이터가 있을 경우 응답한다.
장단점
장점
- 구현 및 설정이 간단하다.
- 기존의 HTTP 프로토콜을 그대로 사용한다.
단점
- 네트워크 트래픽이 많고 서버 자원을 낭비할 수 있다.
- 실시간성을 제공하기 어렵고 지연이 발생할 수 있다.
예제 코드
@RestController
class PollingController {
private var count: Int = 0
@GetMapping("/polling")
fun loadPollingServer(): Int {
val result = count++
return result
}
}
...
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Polling Example</title>
</head>
<body>
<h1>Polling</h1>
<ul id="messages"></ul>
<script>
function startPolling() {
setInterval(() => {
fetch("/polling")
.then(response => response.json())
.then(data => {
const li = document.createElement("li");
li.textContent = 'Data ' + data;
document.getElementById('messages').appendChild(li);
})
.catch(error => console.error('Error:', error));
}, 1000); // 1초마다 요청
}
startPolling();
</script>
</body>
</html>

WebSocket
WebSocket은 양방향 통신을 지원하는 프로토콜로, 클라이언트와 서버 간에 지속적인 연결을 유지하며 실시간 데이터 송수신이 가능하다.
초기 핸드쉐이크는 HTTP를 사용하고, 그 이후에는 WebSocket 프로토콜을 통해 양방향 통신을 수행한다.
장단점
장점
- 양방향 통신을 지원하므로 클라이언트와 서버 간에 실시간으로 데이터를 주고받을 수 있다.
- 서버와 클라이언트가 연결을 유지하며 데이터 전송이 이루어지므로 매우 효율적이다.
단점
- 클라이언트와 서버 모두 WebSocket을 지원해야 한다.
- 비교적 구현이 복잡하다.
예제 코드
@Configuration
@EnableWebSocket
class WebSocketConfig : WebSocketConfigurer {
override fun registerWebSocketHandlers(registry: WebSocketHandlerRegistry) {
registry.addHandler(WebSocketHandlerImpl(), "/ws")
.setAllowedOrigins("*")
}
}
class WebSocketHandlerImpl : TextWebSocketHandler() {
override fun handleTextMessage(session: WebSocketSession, message: TextMessage) {
if (message.payload == "start") {
sendNumbers(session)
}
}
private fun sendNumbers(session: WebSocketSession) {
Executors.newSingleThreadExecutor().submit {
try {
for (i in 1..10) {
val responseMessage = "Data: $i"
session.sendMessage(TextMessage(responseMessage))
Thread.sleep(1000)
}
} catch (e: InterruptedException) {
e.printStackTrace()
}
}
}
override fun afterConnectionClosed(session: WebSocketSession, closeStatus: org.springframework.web.socket.CloseStatus) {
println("WebSocket connection closed: ${session.id}")
}
}
...
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>WebSocket Example</title>
</head>
<body>
<h1>WebSocket</h1>
<button onclick="startSending()">Start</button>
<div id="messages"></div>
<script>
const socket = new WebSocket('ws://localhost:8080/ws');
socket.onopen = function() {
console.log("WebSocket connected!");
};
socket.onmessage = function(event) {
console.log("Received message: " + event.data);
const messagesDiv = document.getElementById("messages");
const newMessage = document.createElement("p");
newMessage.textContent = event.data;
messagesDiv.appendChild(newMessage);
};
socket.onclose = function() {
console.log("WebSocket connection closed");
};
socket.onerror = function(error) {
console.log("WebSocket error: " + error);
};
// 클라이언트가 "Start Sending Numbers" 버튼을 클릭하면 서버에 "start" 메시지를 보냄
function startSending() {
if (socket.readyState === WebSocket.OPEN) {
socket.send("start");
}
}
</script>
</body>
</html>

어떤 것을 선택?
결론부터 말하자면 SSE를 사용하는 것이 적절하다고 생각이 되었다.
Docker API를 통해 클라이언트로 데이터를 전송만 하고 클라이언트에서 서버로 데이터를 주진 않으니 단방향 통신이 필요했다.
(WebSocket은 양방향 통신이 필요할 때 사용되니 이 과정에서 제외)
그리고 Docker에서 어떠한 이벤트가 발생했을 때 바로 이벤트가 수신되어야, 빠른 장애 대응이 가능하기 때문에 실시간성도 필요했다.
(WebSocket은 실시간성이 보장되나, 양방향 통신이 필요 없고, Polling은 실시간성이 보장되지 않기 때문에 이 과정에서 제외)
또한, 이벤트가 발생했을 때만 데이터를 전송하는 것이 효율적이므로, SSE가 제일 적절하다고 생각이 되었다.
05 Jan 2025
자바 메모리 구조에 대해서 정리해보자.
자바 메모리 구조는 크게 메서드 영역, 스택 영역, 힙 영역으로 나뉜다.
메서드 영역
메서드 영역은 공통 데이터를 가진다.
클래스 정보, 프로그램을 실행하는데 필요한 공통 데이터, static, 런타임 상수풀을 가진다.
스택 영역
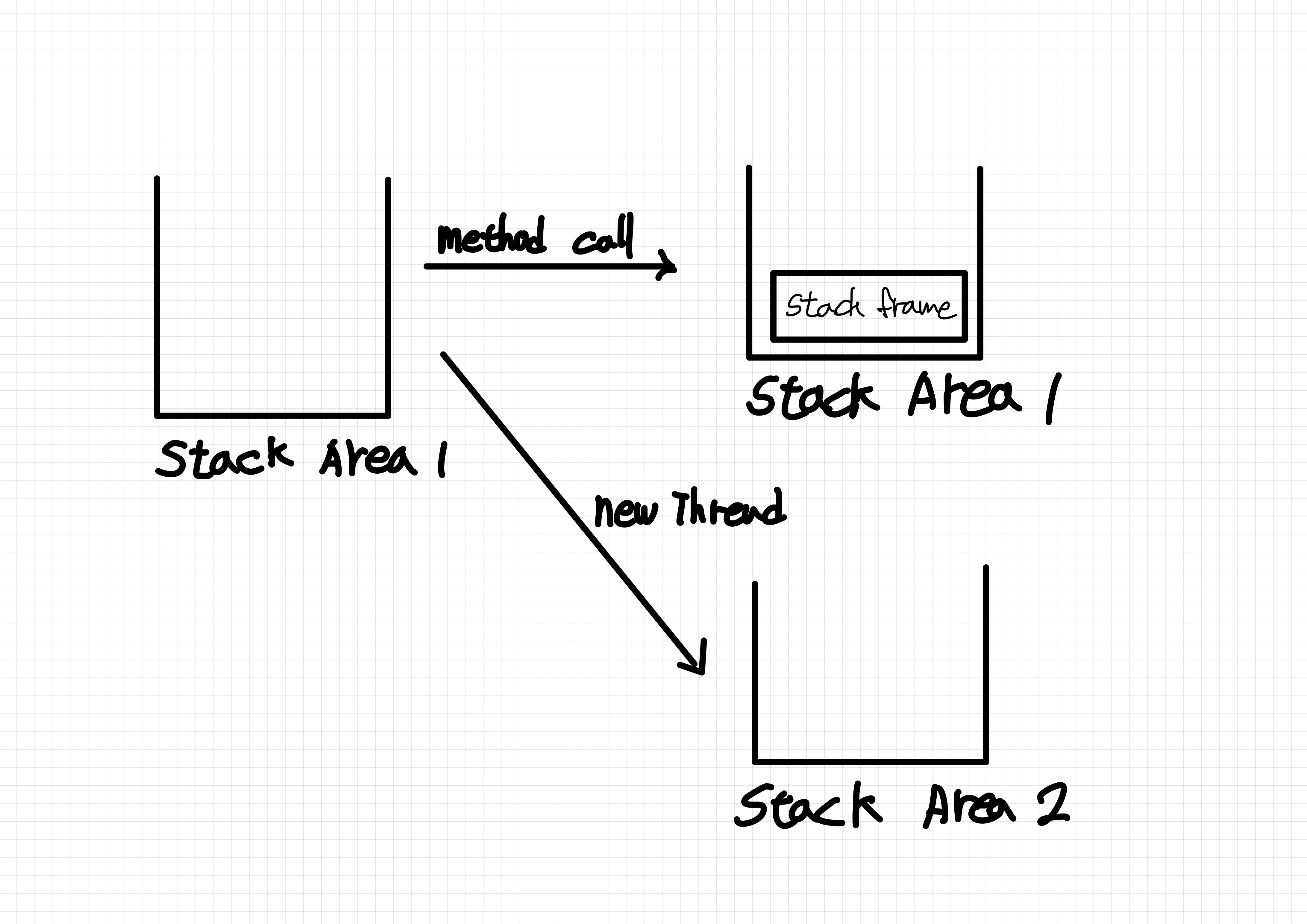
스택 영역은 실제 프로그램이 실행되는 영역이다.
메서드 실행 시 스택영역에 하나의 스택 프레임이 쌓인다.
스택 프레임에는 지역 변수, 중간 연산 결과, 메서드 호출 정보 등이 포함된다.
각 스레드 별로 스택 영역은 새로 생성된다.
힙 영역
힙 영역은 객체 인스턴스와 배열이 생성되는 영역이다.
GC가 이루어지는 주요 영역이다.
지역 변수와 인스턴스/정적 필드
스레드가 생기면 새로운 스택 영역에 스택 프레임이 쌓인다.
스레드가 생성될 때마다 스택 영역이 새로 생기므로, 스택 프레임에 포함되어 있는 지역 변수는 계속 새로 생긴다.
인스턴스 필드와 정적 필드는 새로운 스택 영역이 생기더라도 각각 힙 영역과 메서드 영역에 생성되므로 새로 생기지 않고 공유된다.
04 Jan 2025
들어가며
나는 보통 커밋을 할 때 어떠한 기능이 완료되었거나, 중간에 변경 내용을 임시로 저장할 때 커밋을 하곤 한다.
git을 이용해 커밋을 할 때, 어떠한 기준으로 커밋 시점을 정해야 할까? 라는 의문이 생겼고 알아본 결과와 내 생각을 공유하고자 한다.
최소 단위 커밋
커밋은 보통 최소 단위로 커밋을 하거나, 의미 있는 단위로 작업을 마쳤을 때 커밋을 해야 한다고 한다.
그래야 나중에 revert하기가 쉬워지고, 커밋 로그를 봤을 때도 어떠한 내용이 반영되었는지 알기가 쉬워진다.
feat, fix, doc, test 와 같이 작업을 분류하고 어떠한 내용을 했는지 한 줄로 표현하기 쉬운 단위로 해야 한다고 한다.
예) [feat: 회원 이메일 체크 서비스 로직 추가]
큰 단위의 작업은?
항상 작은 단위로 커밋을 해야 할까? 큰 단위의 작업이라도 작은 단위로 나누어서 커밋하는 것이 좋다.
큰 작업을 완료하고 커밋 메시지를 작성하게 되면 [fix: User 도메인 로직 수정] 와 같이 뭉뚱그려 작성하게 된다.
이렇게 작성하게 되면, 나중에 확인했을 때 구체적으로 어떤 작업을 했는지 파악하기가 힘들어진다.
또한, 커밋 로그를 봤을 때, 바운더리가 넓은 작업은 같은 커밋 메시지가 여러 번 나올 수 있는 문제가 발생할 수 있다.
예를 들어, [fix: User 도메인 로직 수정]로 작성하게 되면, User 도메인 로직에 닉네임 체크 로직, 회원 이메일 체크 로직 등 모든 User 도메인 로직의 코드를 수정했을 경우 모두 [fix: User 도메인 로직 수정]로 작성하게 된다.
이렇게 되면 pr 로그를 봤을 때 [fix: User 도메인 로직 수정]만 여러 줄 있는 것을 보게 된다.
따라서 큰 작업을 진행 중에도 중간중간 커밋을 하여 아래와 같이 작성하는 것이 좋다.
[fix: User 도메인의 Nickname 중복 확인 로직 수정]
[fix: User 도메인의 이메인 형식 확인 로직 수정]
커밋 body를 사용하면 되지 않나?
커밋의 제목을 큰 단위로 작성하고 하위 작업을 커밋 메시지 body 부분에 작성하면 되지 않을까?
이 방법도 가능은 하겠지만 지양하는 것이 좋아보인다.
왜냐하면, 커밋 로그가 수십, 수백개가 쌓인 가운데, 어떠한 로직을 구현했는지 커밋을 하나하나 뜯어보는 것은 매우 비효율적이기 때문이다.
body 부분은 최소 단위의 커밋의 추가 상세 설명을 적어 놓는 것이 좋을 것이다.
커밋 메시지는 이렇게 될 것이다.
[fix: User 도메인의 Nickname 중복 확인 로직 수정]
유저 도메인의 닉네임 체크 로직에 ~한 문제가 있어서 ~로 수정을 진행.
해당 로직 수정으로 ~ 클래스에 ~한 부분을 수정 진행.
[fix: User 도메인의 이메일 형식 확인 로직 수정]
유저 도메인의 이메일 체크 로직에 정규 표현식이 잘못되어 있는 부분을 ~의 형식으로 수정 진행.
결론
커밋은 합칠 수는 있지만 분리할 수는 없다. 이 점을 생각하고 틈틈히 커밋을 해주자.