25 Nov 2024
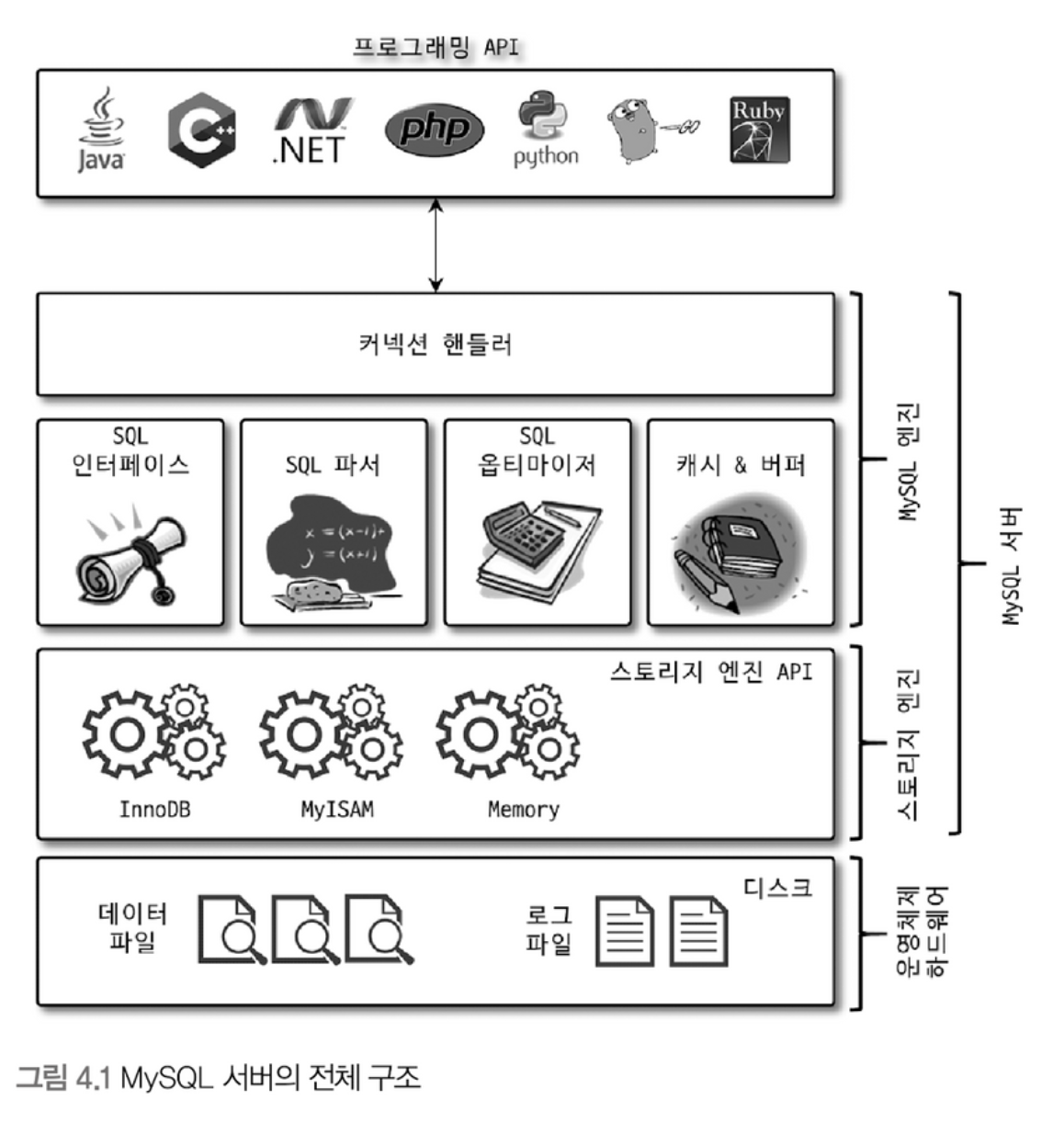
MySQL 서버는 크게 MySQL 엔진과 스토리지 엔진으로 구분할 수 있다.
MySQL 엔진
MySQL 엔진은 커넥션 핸들러, SQL 파서 및 전처리기, 옵티마이저가 중심을 이룬다.
- 커넥션 핸들러 : 클라이언트로부터의 접속 및 쿼리 요청을 처리
- 옵티마이저 : 쿼리의 최적화된 실행
스토리지 엔진
실제 데이터를 디스크 스토리지에 저장하거나 디스크 스토리지로부터 데이터를 읽어오는 부분은 스토리지 엔진이 담당한다.
MySQL 서버에서 MySQL 엔진은 하나지만 스토리지 엔진은 여러 개를 동시에 사용할 수 있다.
MySQL 스레딩 구조
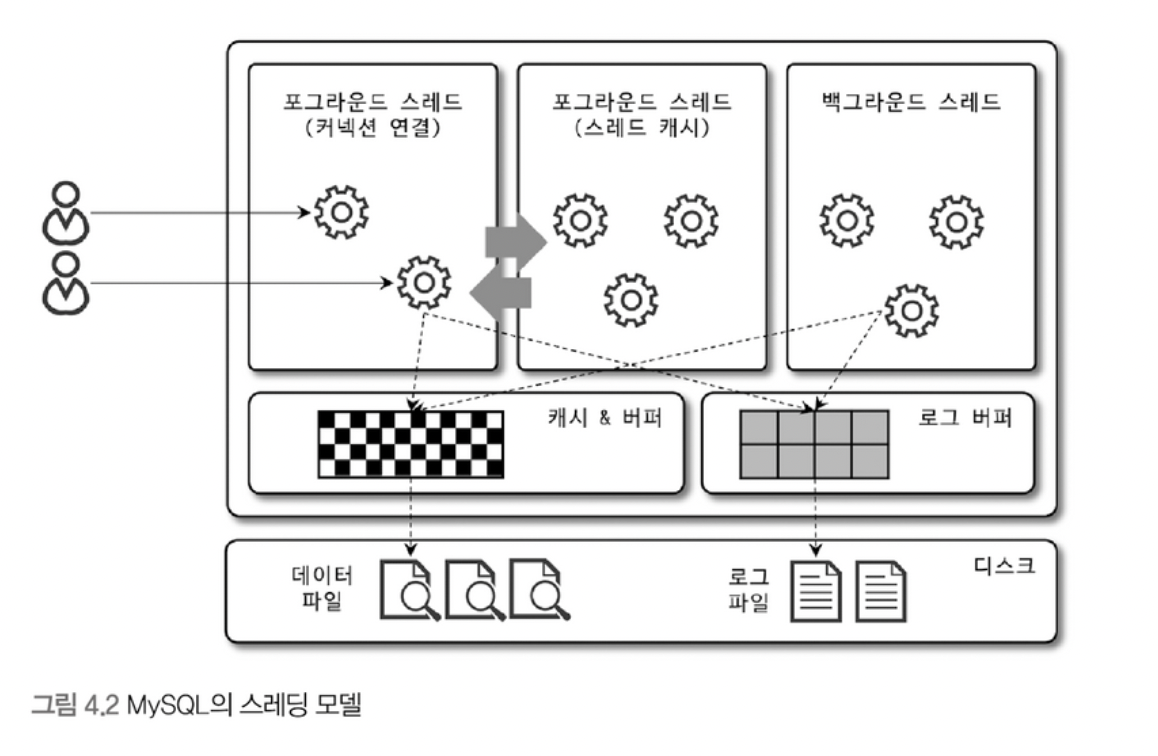
MySQL 서버는 프로세스 기반이 아니라 스레드 기반으로 작동하며 크게 포그라운드 스레드와 백그라운드 스레드로 구분할 수 있다.
- 포그라운드 스레드(클라이언트 스레드)
- 데이터를 MySQL의 데이터 버퍼나 캐시로부터 가져오며, 버퍼나 캐시에 없는 경우에는 직접 디스크의 데이터나 인덱스 파일로부터 데이터를 읽어와서 작업을 처리한다.
- 포그라운드 스레드는 최소한 MySQL 서버에 접속된 클라이언트 수만큼 존재하며, 주로 각 클라이언트 사용자가 요청하는 쿼리 문장을 처리한다.
- 백그라운드 스레드
- InnoDB는 여러 가지 작업이 백그라운드로 처리된다.
- Insert 버퍼를 병합하는 스레드
- 로그를 디스크로 기록하는 스레드
- 데이터를 버퍼로 읽어오는 스레드
- 잠금이나 데드락을 모니터링하는 스레드
메모리 할당 및 사용 구조
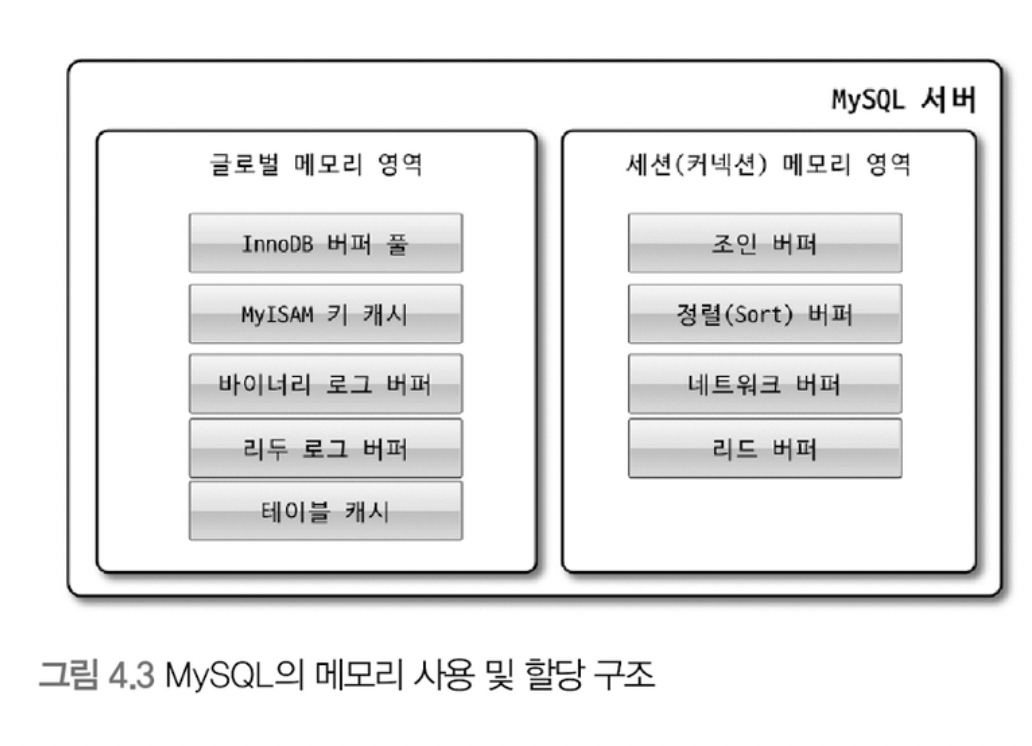
MySQL에서 사용되는 메모리 공간은 크게 글로벌 메모리 영역과 로컬 메모리 영역으로 구분할 수 있다.
- 글로벌 메모리 영역
- 글로벌 메모리 영역의 모든 메모리 공간은 MySQL 서버가 시작되면서 운영체제로부터 할당된다.
- 일반적으로 클라이언트 스레드의 수와 무관하게 하나의 메모리 공간만 할당된다.
- 로컬 메모리 영역
- MySQL 서버상에 존재하는 클라이언트 스레드가 쿼리를 처리하는 데 사용하는 메모리 영역이다.
- 로컬 메모리는 각 클라이언트 스레드별로 독립적으로 할당되며 절대 공유되어 사용되지 않는다.
쿼리 실행 구조
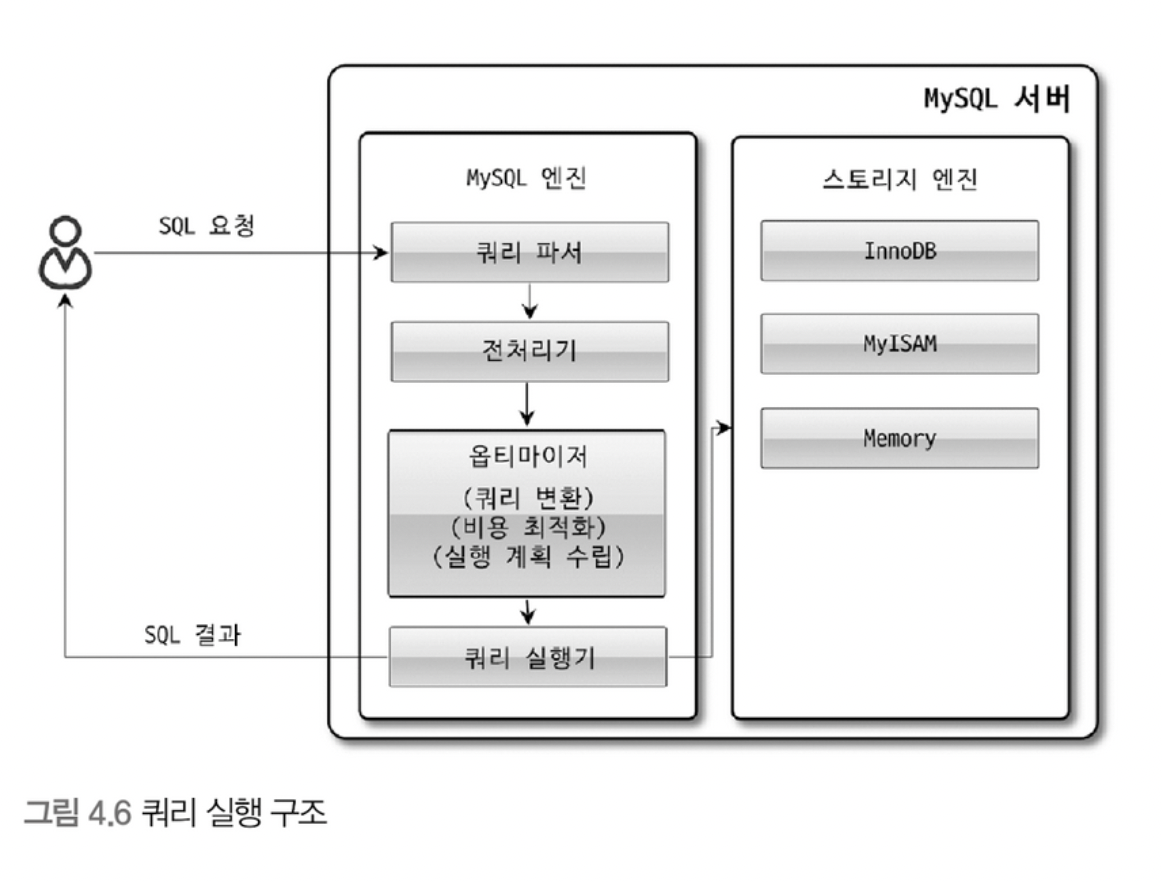
- 쿼리 파서
- 쿼리 파서는 사용자 요청으로 들어온 쿼리 문장을 토큰으로 분리해 트리 형태의 구조로 만들어 내는 작업을 의미한다.
- 쿼리 문장의 기본 문법 오류는 이 과정에서 발견되고 전달된다.
- 전처리기
- 파서 과정에서 만들어진 파서 트리를 기반으로 쿼리 문장에 구조적인 문제점을 확인한다.
- 객체의 존재 여부와 객체의 접근 권한 등을 확인하는 과정을 수행한다.
- 옵티마이저
- DBMS의 두뇌, 사용자의 요청으로 들어온 쿼리 문장을 낮은 비용으로 빠르게 처리할지를 결정한다.
- 실행 엔진
- 실행 엔진과 핸들러는 손과 발이다.
- 실행 엔진은 만들어진 계획대로 각 핸들러에게 요청해서 받은 결과를 또 다른 핸들러 요청의 입력으로 연결하는 역할을 수핸한다.
- 핸들러(스토리지 엔진)
- MySQL 서버의 가장 밑단에서 MySQL 실행 엔진의 요청에 따라 데이터를 디스크로 저장하고 디스크로부터 읽어오는 역할을 담당한다.
InnoDB 스토리지 엔진 아키텍처
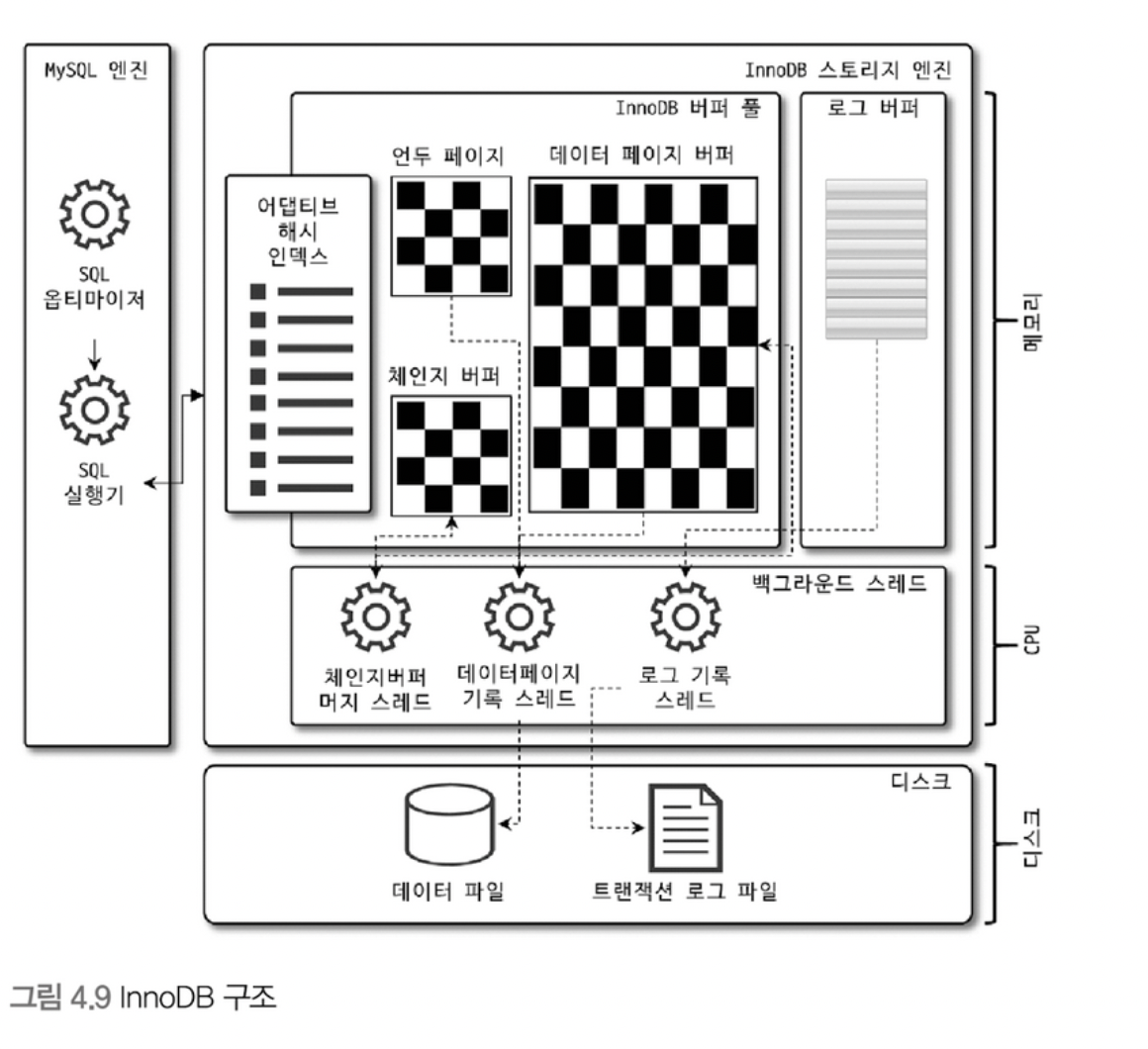
InnoDB는 MySQL 스토리지 엔진으로 레코드 기반의 잠금을 제공하며, 높은 동시성 처리를 할 수 있고 안정적이며 성능이 뛰어나다.
- InnoDB의 모든 테이블은 기본적으로 프라이머리 키를 기준으로 클러스터링되어 저장된다.
- InnoDB 스토리지 엔진 레벨에서 외래 키에 대한 지원을 한다.
- MVCC(Multi Version Concurrency Control)
- 일반적으로 레코드 레벨의 트랜잭션을 지원하는 기능이며, MVCC의 가장 큰 목적은 잠금을 사용하지 않는 일관된 읽기를 제공하는 데 있다.
- InnoDB는 언두 로그를 이용해 이 기능을 구현한다.
- 잠금 없는 일관된 읽기
- InnoDB 스토리지 엔진은 MVCC 기술을 이용해 잠금을 걸지 않고 읽기 작업을 수행한다.
- 잠금을 걸지 않기 때문에 InnoDB에서 읽기 작업은 다른 트랜잭션이 가지고 있는 잠금을 기다리지 않고, 읽기 작업이 가능하다.
- 자동 데드락 감지
- InnoDB 스토리지 엔진은 내부적으로 잠금이 교착 상태에 빠지지 않았는지 체크한다.
- InnoDB에는 손실이나 장애로부터 데이터를 보호하기 위한 메커니즘이 탑재돼 있다.
언두로그
언두로그는 트랜잭션과 격리 수준을 보장하기 위해 DML로 변경되기 이전 버전의 데이터를 별도로 백업하는 것을 말한다.
언두로그는 트랜잭션과 격리 수준을 보장해준다.
리두로그
리두 로그는 영속성과 관련이 있는데, MySQL 서버가 비정상적으로 종료 됐을 때 데이터 파일에 기록하지 못한 데이터를 잃지 않게 해주는 안전장치다.
InnoDB 버퍼 풀
InnoDB 스토리지 엔진에서 버퍼 풀은 가장 핵심적인 부분으로, 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시해두는 공간이다.
쓰기 작업을 지연시켜 일괄 작업으로 처리할 수 있게 해주는 버퍼 역할도 같이 한다.
- 버퍼 풀의 구조
- InnoDB 스토리지 엔진은 버퍼 풀이라는 거대한 메모리 공간을 페이지 크기의 조각으로 쪼개어 InnoDB 스토리지 엔진이 데이터를 필요로 할 때 해당 데이터 페이지를 읽어서 각 조각에 저장한다.
- 버퍼 풀의 페이지 크기 조각을 관리하기 위해 InnoDB 스토리지 엔진은 크게 LRU 리스트와 플러시 리스트, 프리 리스트라는 3가지 자료 구조를 관리한다.
- InnoDB 스토리지 엔진에서 데이터를 찾는 과정
- 필요한 레코드가 저장된 데이터 페이지가 버퍼 풀에 있는지 검사
- 디스크에서 필요한 데이터 페이지를 버퍼 풀에 적재하고, 적재된 페이지에 대한 포인터를 LRU 헤더 부분에 추가
- 버퍼풀의 LRU 헤더 부분에 적재된 데이터 페이지가 실제로 읽히면 MRU (Most Recently Used) 헤더 부분으로 이동
- 버퍼풀에 상주하는 데이터 페이지는 사용자 쿼리가 얼마나 접근했었는지에 따라 나이가 부여되며, 나이가 오래되면 해당 페이지는 버퍼 풀에서 제거됨
- 버퍼 풀의 데이터 페이지가 쿼리에 의해 사용되면 나이가 초기화되고 MRU의 헤더 부분으로 옮겨진다.
- 버퍼풀과 리두 로그
- InnoDB 버퍼 풀과 리두 로그는 매우 밀접한 관계를 갖는다.
- InnoDB 버퍼 풀은 서버의 메모리가 혀용하는 만큼 크게 설정할수록 쿼리의 성능이 빨라진다.
- DB 성능 향상을 위해 데이터 캐시와 쓰기 버퍼링이라는 두 가지 방법이 있는데, 버퍼 풀은 데이터 캐시 기능만 향상시키는 것이다.
- 버퍼 풀 플러시
- InnoDB 스톨리지 엔진은 버퍼 풀에서 아직 디스크로 기록되지 않은 더티 페이지들을 성능상의 악영향 없이 디스크에 동기화하기 위해 2개의 플러시 기능을 백그라운드로 실행한다.
- 플러시 리스트 플러시
- 리두 로그 공간의 재활용을 위해 오래된 리두 로그 공간을 비워줘야 한다.
- 이때 공간을 지우려면 반드시 InnoDB 버퍼 풀의 더티 페이지가 먼저 디스크로 동기화돼야 한다.
- 이를 위해 플러시 리스트 플러시 함수를 호출해서 오래전에 변경된 데이터 페이지 순서대로 디스크에 동기화하는 작업을 수행한다.
- LRU 리스트 플러시
- InnoDB 스토리지 엔진은 LRU 리스트에서 사용 빈도가 낮은 데이터 페이지들을 제거한다.
Double Wirte Buffer
InnoDB의 리두 로그는 리두 로그 공간의 낭비를 막기 위해 페이지의 변경된 내용만 기록한다.
InnoDB 스토리지 엔진에서는 이러한 문제를 막기 위해 Double-Write 기법을 이용한다.
InnoDB 스토리지 엔진은 실제 데이터 파일에 변경 내용을 기록하기 전에 더티 페이지를 우선 묶어 한 번의 디스크 쓰기로 시스템 테이블스페이스의 DoubleWrite 버퍼에 기록하고 각 더티 페이지를 파일의 적당한 위치에 하나씩 랜덤으로 쓰기를 실행한다.
체인지 버퍼
InnoDB는 변경해야 할 인덱스 페이지가 버퍼 풀에 있으면 바로 업데이트를 하지만 디스크로부터 읽어와서 업데이트해야 한다면 임시 공간에 저장해 두고 바로 사용자에게 결과를 반환하는 방식으로 성능을 높인다.
이때 사용하는 임시 메모리 공간을 체인지 버퍼라고 한다.
11 Nov 2024
Spring Cloud Config와 Git을 사용해서 설정 정보 파일을 관리해보자.
Spring Cloud Config란?
Spring Cloud Config는 분산 시스템 환경에서 애플리케이션의 설정을 중앙 집중식으로 관리하고 제공하는 데 사용되는 도구다.
예를 들어, Spring Boot에서 자주 사용하는 application.properties나 application.yml 파일을 외부에서 관리할 수 있게 해주며, 애플리케이션의 설정을 한 곳에서 쉽게 수정하고 공유할 수 있게 해준다.
그리고 각 서비스를 다시 빌드하지 않고, 바로 적용할 수 있는 기능을 지원한다.
또한 각 환경(개발, 테스트, 운영 등) 별로 다른 설정을 관리할 수 있다.
Spring Cloud Config를 다양한 방법으로 사용하는 것을 알아보자.
구현
Spring Cloud Config를 Git을 통해 설정 파일을 관리할 수 있다.
Git에 설정 정보 파일을 올려두고 이 정보를 가져오는 방식으로 사용한다.
Git을 사용해 진행하기 위해 먼저 Local에 Git Repository를 생성하도록 하자.
Git 설정은 끝났고, Spring Cloud Config 서버를 만들어보자.
Spring Boot 프로젝트에서 Config Server 의존성을 추가해준다.
그리고 애플리케이션 파일에서 @EnableConfigServer 어노테이션을 추가해주자.
해당 프로젝트에서 application.yml 파일도 수정해주자.
작성을 완료했다면 서버를 띄우고 http://localhost:8888/application/default 주소로 접속해보자.
아래와 같이 나왔다면 성공이다.
이렇게 띄운 설정 정보를 다른 서버에서 사용해보자.
새로운 프로젝트를 하나 생성하고 의존성을 추가하자.
그리고 yml에서 설정 정보를 가져올 Spring Cloud Config의 주소를 입력해주자.
이제 테스트를 위해 간단한 컨트롤러를 만들어주자.
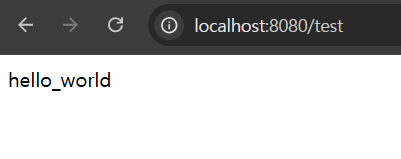
그리고 이 서버의 주소(http://localhost:8080/test)로 요청을 보내보자.
아래와 같이 나온다면 성공이다!
이렇게 Git을 이용한 방법을 로컬에서뿐만 아니라 원격 저장소(Github)와 같은 곳에서도 가져올 수 있다.
config server의 yml을 아래와 같이 바꿔주고 해당 파일을 Github Repository에 업로드 하자.
이 또한 config server를 재구동하고 http://localhost:8080/test로 접속하면 hello_world 라는 문구가 나온다.
04 Nov 2024
코루틴은 취소에 협력해야 한다.
이 말은 취소 가능한 코루틴이 스스로 취소가 요청됐는지 검사해서 적절히 반응해줘야 한다는 말이다.
코루틴 Job의 cancel() 메서드를 호출하면 Job을 취소할 수 있다.
이 코드를 실행해보면 코루틴이 취소에 협력하지 않기 때문에 계속 실행되는 모습을 볼 수 있다.
이런 문제를 해결하는 방법으로 다음 작업을 시작하기 전에 코루틴이 취소됐는지 확인하는 방법이 있다.
isActive 확장 프로퍼티는 현재 잡이 활성화된 상태인지 검사한다.
부모 코루틴이 cancel() 메서드를 호출하면 squarePrinter의 상태가 취소 중으로 바뀌고 그다음 isActive 검사를 통해 루프를 종료시킬 수 있다.
다른 방법으로는 delay(), join(), yield() 등의 일시 중단함수를 이용해 CancellationException을 발생시키는 방법이 있다.
코루틴 취소에 대한 다른 사항으로, 부모 코루틴이 취소되면 자동으로 모든 자식의 실행을 취소한다.
이 과정은 부모에게 속한 모든 Job 계층이 취소될 때까지 계속된다.
아래 코드는 세 가지 자식 Job 중 어느 하나도 완료 상태가 되지 못한다.
28 Oct 2024
젠킨스를 이용하여 간단한 CI/CD 파이프라인을 구현해보자.
Ubuntu, Jenkins, Docker, Github 를 이용하여 로컬에서 Github로 push하면 Jenkins가 해당 commit을 감지한다.
Jenkins에선 해당 내용을 빌드하고 DockerHub로 push 한다. 또한 Ubuntu 서버에서 해당 도커 이미지를 pull & run 하여 서버를 실행한다.
코드 작성
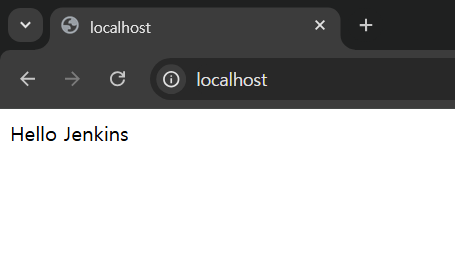
단순하게 SpringBoot의 RestController에 루트 url로 요청을 하면 “Hello Jenkins”라는 글자가 나오는 API를 구현한다.
포트 번호는 80 이다.
이 API로 빌드 & 배포가 된 결과를 확인해보자
도커로 배포할 것이기 때문에 도커파일도 작성해둔다.
Jenkins 설치
Jenkins를 도커로 설치해보자.
도커로 젠킨스 컨테이너를 실행하고 http://localhost:8080 주소로 들어가면 Jenkins 설치 창이 나온다.
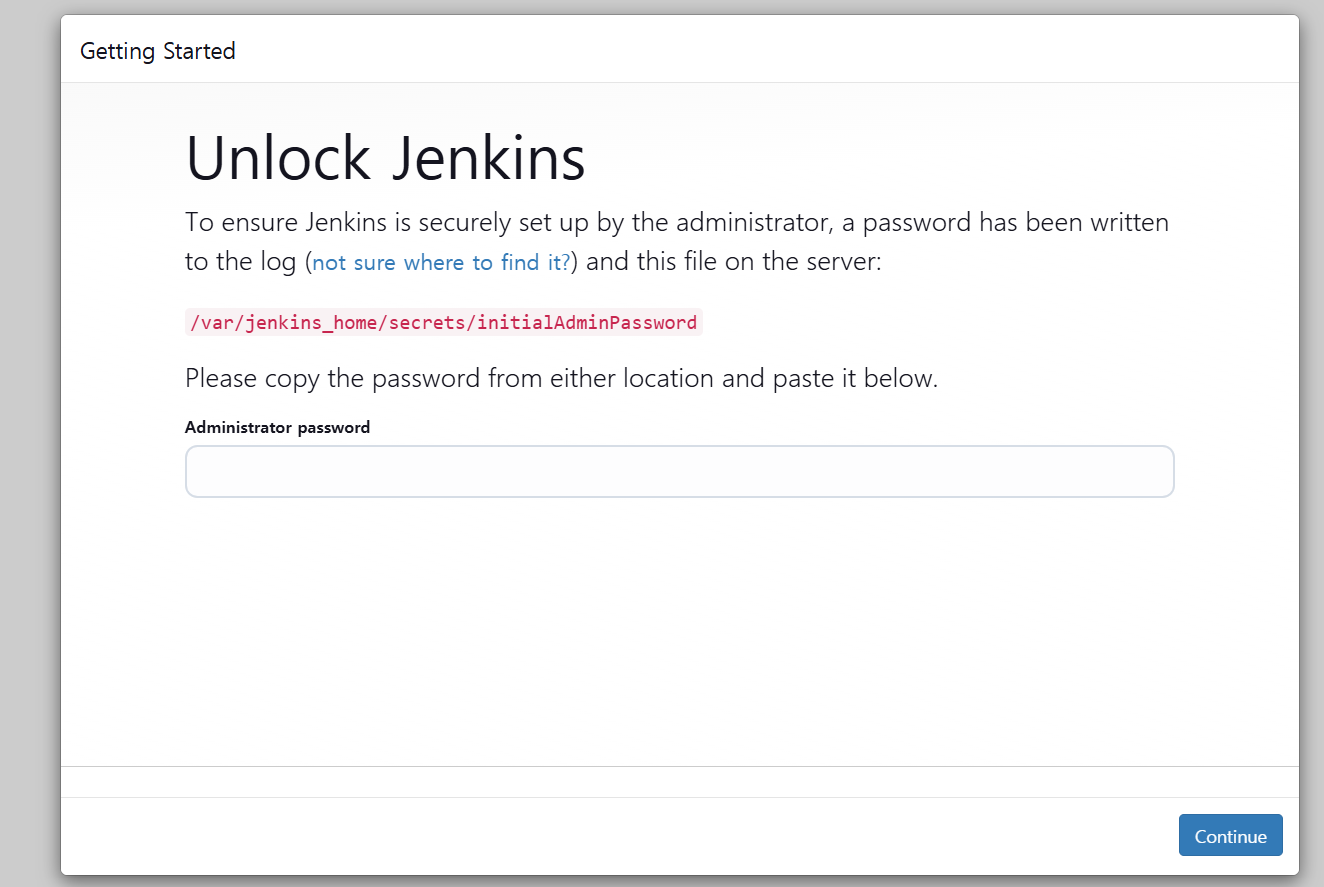
여기서 초기 패스워드는 젠킨스 서버를 띄우는 로그에서 확인할 수 있다.
아니면 /var/lib/jenkins/secrets/initialAdminPassword 경로로 가서 확인할 수도 있다.
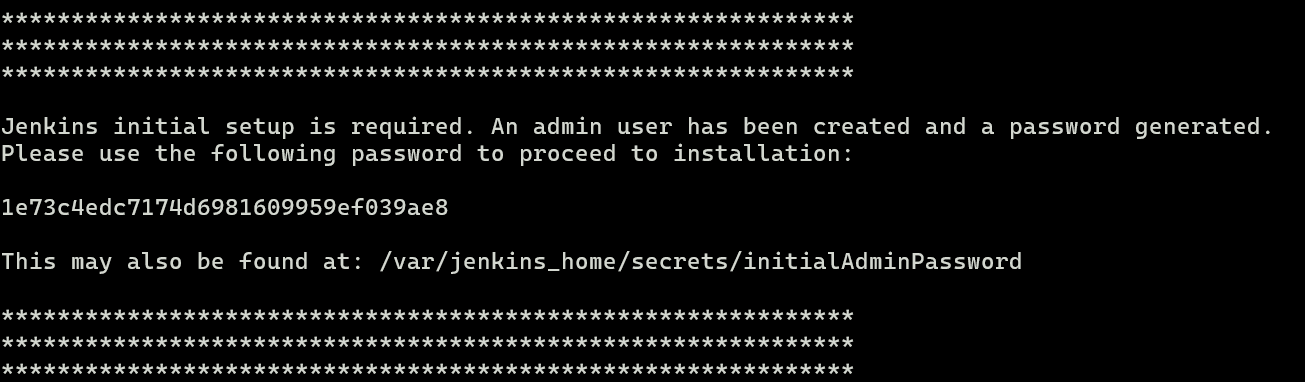
이 초기 비밀번호를 젠킨스 설치창에 입력하자.
이후 install suggested plugins을 클릭하면 설치가 진행된다.
설치가 완료되면 계정, 암호 설정을 진행하면 대시보드가 나타난다.
깃허브 설정
깃허브에서 public repository를 하나 생성해서 만들어 놓은 스프링부트 프로젝트를 push 하자.
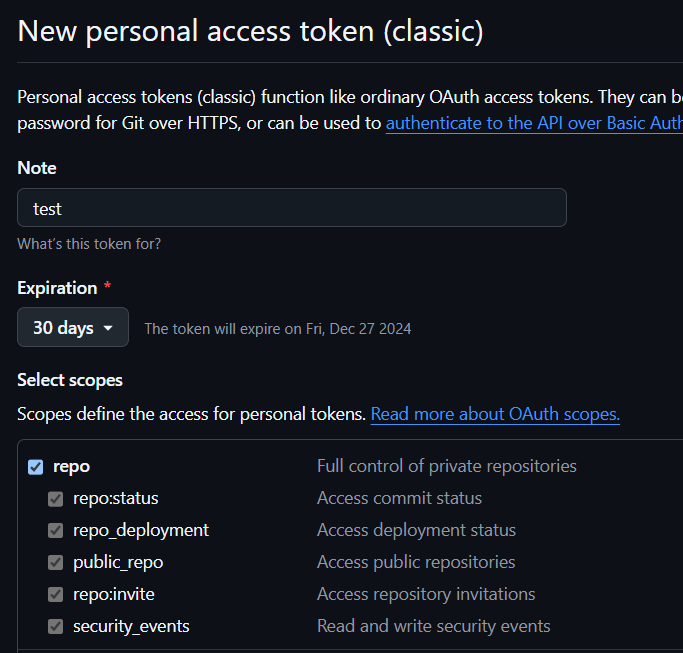
다음으론 젠킨스에서 깃허브에 접근할 수 있게 깃허브 토큰을 하나 발급하자.
Settings -> Developer settings -> Personal access tokens -> Tokens (classic) -> Generate new token (classic)
위의 순서로 발급하면 된다. 권한은 repo를 체크하자.
젠킨스 토큰 설정
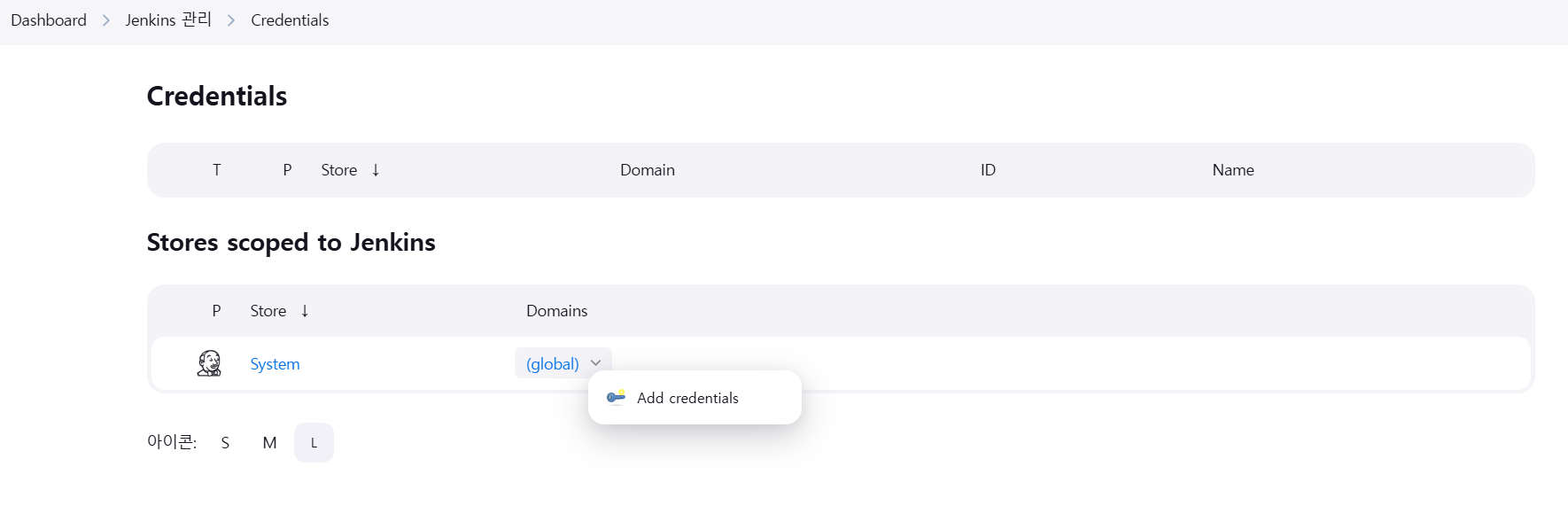
방금 발급한 토큰을 젠킨스 Credential에 등록하자.
Jenins 관리 -> Credentials -> Add credentials를 클릭하면 추가할 수 있다.
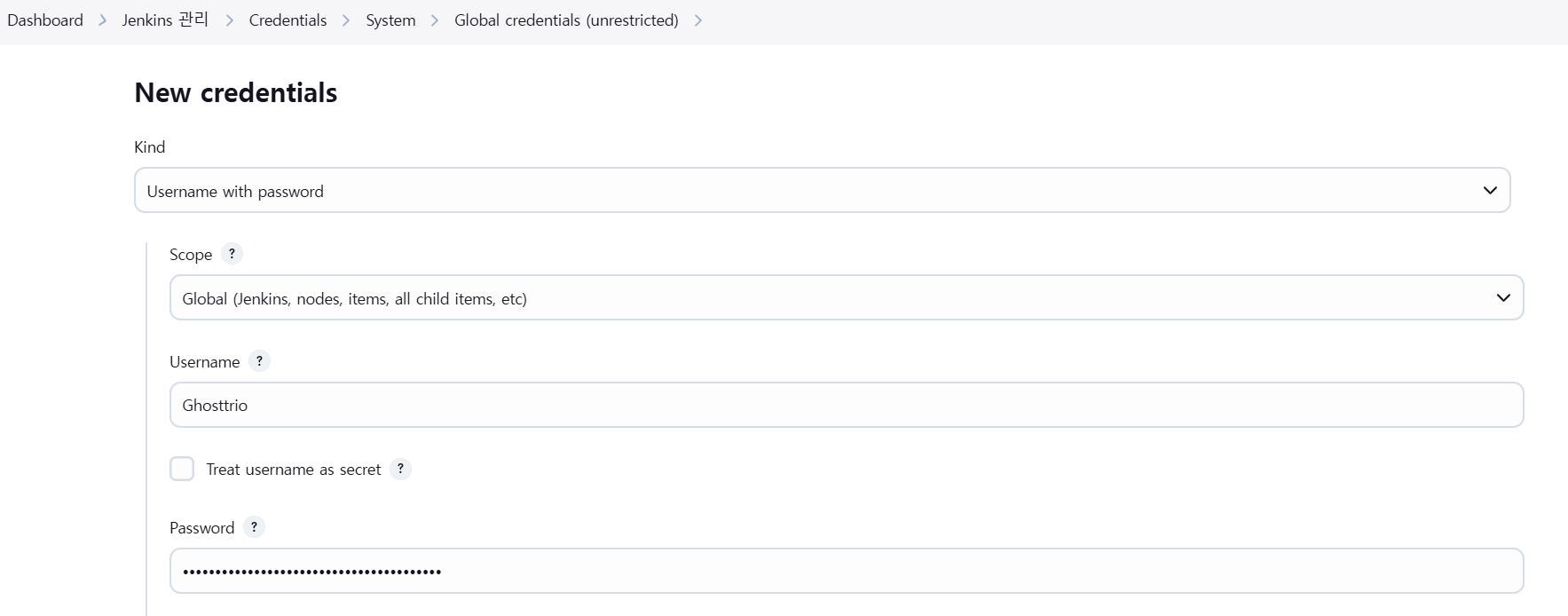
여기서 Username에 Github id를 입력하고 password에 토큰 값을 입력한다.
깃허브 웹훅 설정
이제 깃허브에 push 이벤트가 발생했을 때 젠킨스에서 감지할 수 있도록 webhook 설정을 해보자.
깃허브 레파지토리의 Settings의 Webhook 탭에서 Add Webhook을 클릭하자.
Payload URL에 Jenkins 서버의 주소를 입력해주자.
SSH 설정
Jenkins에서 빌드한 결과물을 Ubuntu 서버에서 실행하기 위해 Jenkins 서버와 Ubuntu 서버를 ssh를 이용하여 연결해보자.
우선 Jenkins plugin에서 Publish Over SSH 설치하자.
설치가 완료되면 Jenkins 관리 -> System 에 들어가면 Publish Over SSH 탭이 생성된 것을 확인할 수 있다.
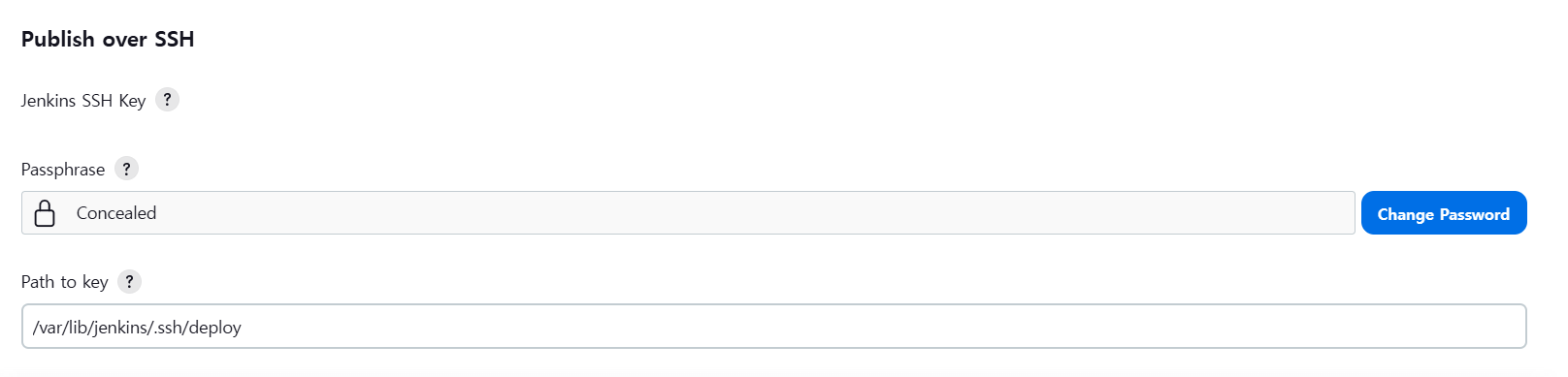
SSH 연결을 하려면 젠킨스 서버에서 생성한 ssh 키를 배포하고자 하는 Ubuntu 서버에 복사하는 작업을 해야 한다.
SSH 접속하기
SSH 키를 복사했다면 Jenkins에 돌아와 확인해보자
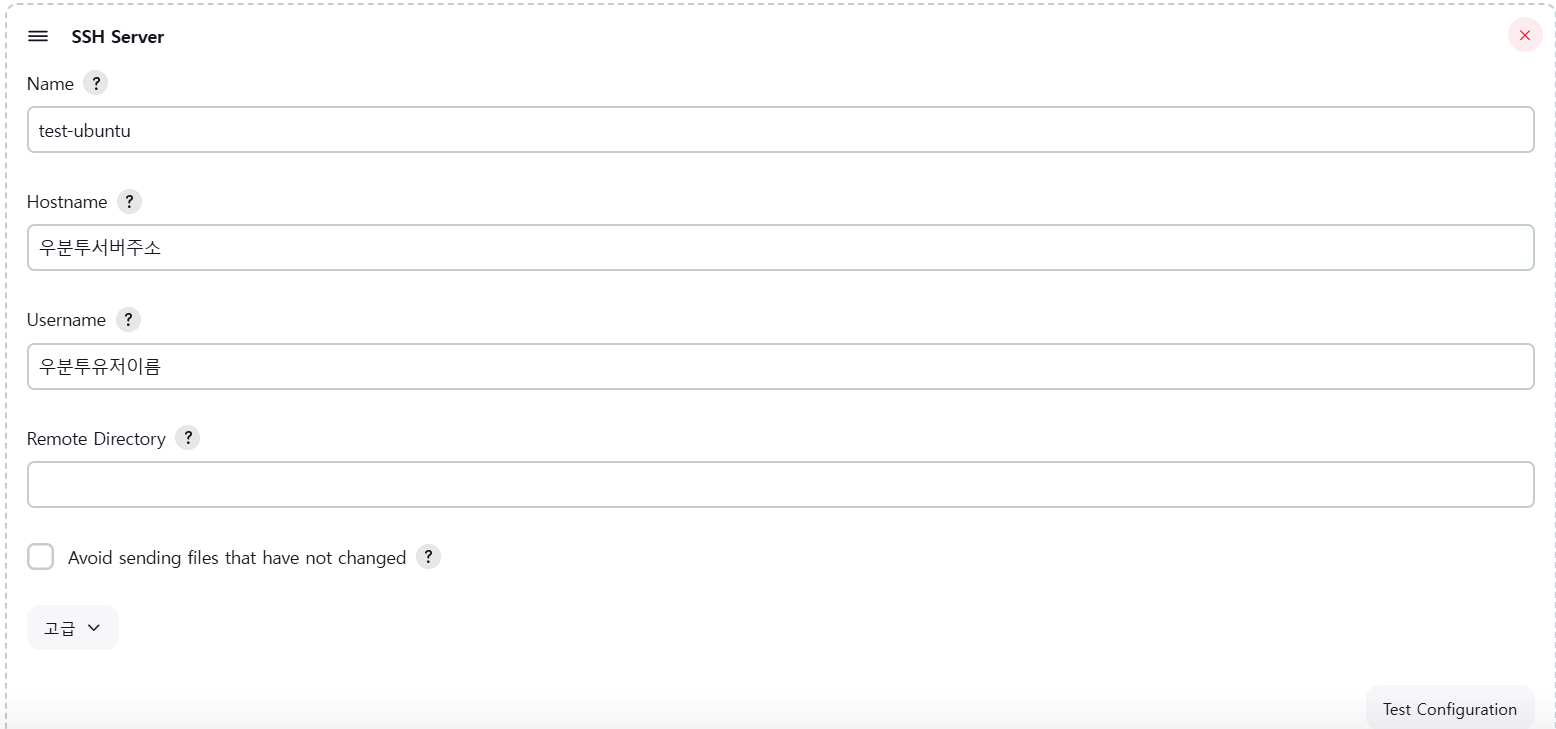
내용을 입력하고 Test Configuration 을 클릭했을 때 Success 가 나오면 성공이다.
젠킨스 파이프라인 생성
젠킨스 파이프라인을 작성해보자.
프리스타일 프로젝트, 파이프라인 프로젝트 등을 선택할 수 있는데, 파이프라인 프로젝트가 좀 더 세밀하게 제어할 수 있어서 선호하는 편이다.
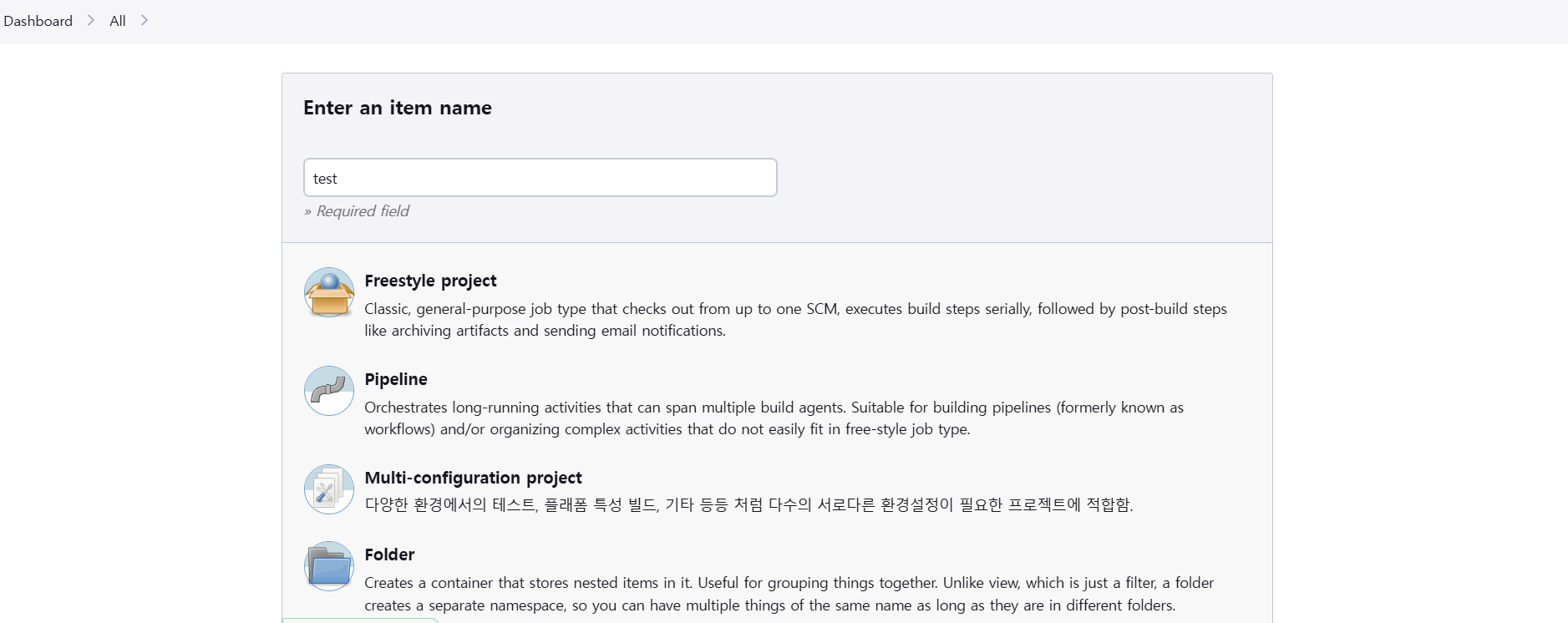
Github project에 레파지토리의 url을 적고 Build Trigger 탭에서 GitHub hook trigger for GITScm polling을 체크한다.
Pipeline 탭에서는 아래와 같이 작성한다.
각 단계를 설명하자면,
git stage에서는 github에 변경된 내용을 감지해서 Jenkins 서버로 가져온다.
build stage에서는 gradle 권한을 주고 빌드 후 dockerhub로 빌드한 이미지를 push 한다.
deploy stage에서는 Publish Over SSH 에서 설정한 configName과 execCommand에 이미 올라가 있는 docker 컨테이너를 삭제함과 동시에 새로운 이미지를 run 한다.
테스트
현재는 루트 url에 요청을 보내면 Hello Jenkins 라는 글자가 출력되는 형태다.
해당 메시지를 Hello CICD로 수정 후 PUSH를 하자.
직후 Jenkins에서 해당 push를 감지하면서 빌드 & 배포를 시작한다.
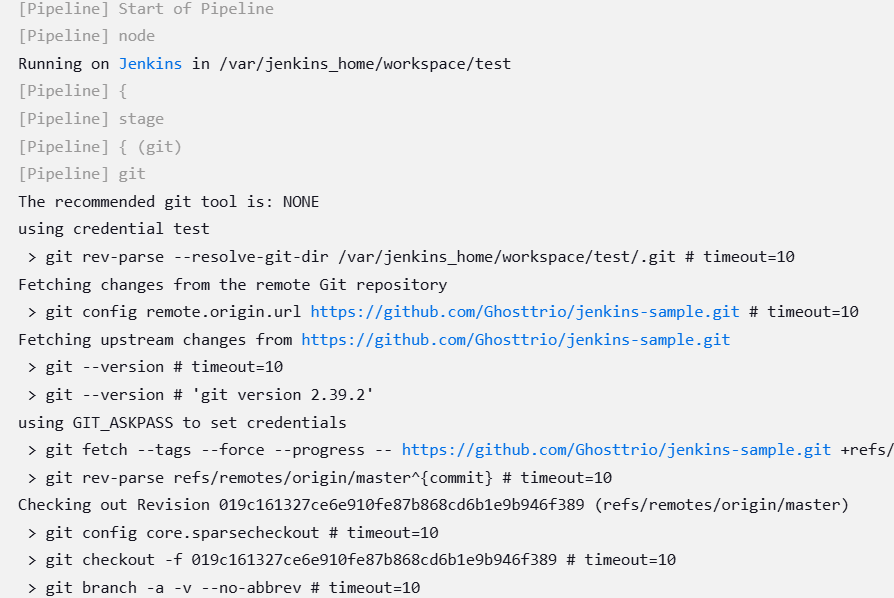
Jenkins 파이프라인 작업이 성공한 것을 확인한 후 서버에 접속해보면 Hello CICD로 바뀐 것을 확인할 수 있다.

21 Oct 2024
Saga 패턴에 대해서 알아보고 간단하게 구현해보자.
Saga 패턴이란?
Saga 패턴은 분산 시스템에서 연속된 서비스 호출이 하나의 트랜잭션처럼 동작되도록 설계된 패턴이다.
긴 트랜잭션을 여러 개의 작은 서비스로 나누어 처리하는 방식으로, 각각의 서비스가 독립적으로 트랜잭션을 수행하지만, 그 전체를 하나의 트랜잭션처럼 다루는 효과를 얻을 수 있다.
Saga 패턴의 특징
- 트랜잭션 분할 : 대규모 분산 시스템에서는 하나의 트랜잭션을 여러 서비스에 분배하여 처리하므로, 긴 트랜잭션을 분할하여 리소스나 네트워크를 효율적으로 관리할 수 있다.
- 각 서비스의 독립성 : 각 서비스가 개별적으로 관리되고, 하나의 서비스에서 실패가 발생하면 이를 보상하는 방식으로 처리된다.
- 보상 처리 : 트랜잭션이 실패했을 겨우, 이미 완료된 트랜잭션을 취소하기 위한 보상 처리 방법을 정의한다.
- 비동기 메시징 : 여러 서비스들이 비동기적으로 통신하며, 각 서비스 간의 의존성이나 트랜잭션을 유지하기 위해 메시징 시스템을 사용하는 경우가 많다.
Saga 패턴의 구현 방식
- Choreography: 각 서비스가 자신이 해야 할 일을 처리하고, 다음 서비스로 메시지를 보내는 방식
- Orchestration : 중앙 제어자가 각 서비스의 흐름을 관리한다.
이번 포스팅에선 Java, SpringBoot, Kafka를 이용하여 Choreography 방식 예시를 알아보자.
먼저 구현할 도메인은 order, stock, delivery 세 가지 도메인이다.
order 도메인에서 주문을 처리하면 stock 도메인에서 재고 처리가 되고, delivery 도메인에서 배달 처리가 된다.
다이어그램으로 살펴보면 다음과 같다.
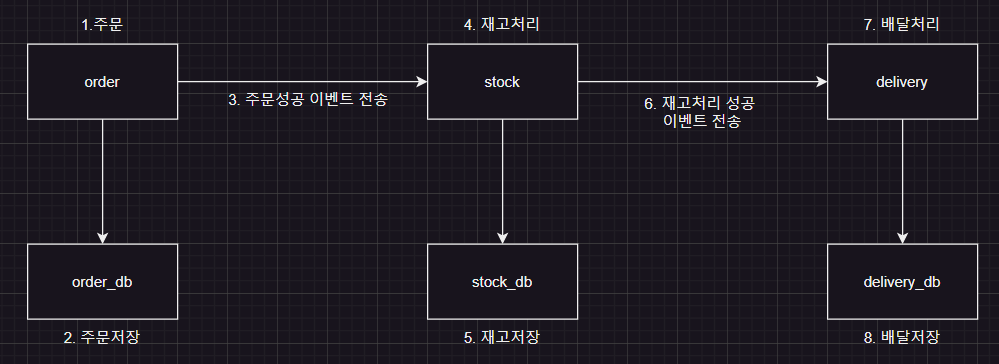
실패할 경우는, delivery에서 실패가 일어났다고 가정한다.
delivery에서 실패하면 stock 도메인으로 실패 이벤트(rollback)를 전송하고 stock 도메인에서 실패 이벤트에 따른 DB 정보를 rollback 한다.
그리고 order 도메인으로 stock rollback 이벤트를 보내고 order 도메인에서도 실패 이벤트에 따른DB 정보를 rollback 한다.
다이어그램으로 살펴보면 다음과 같다.
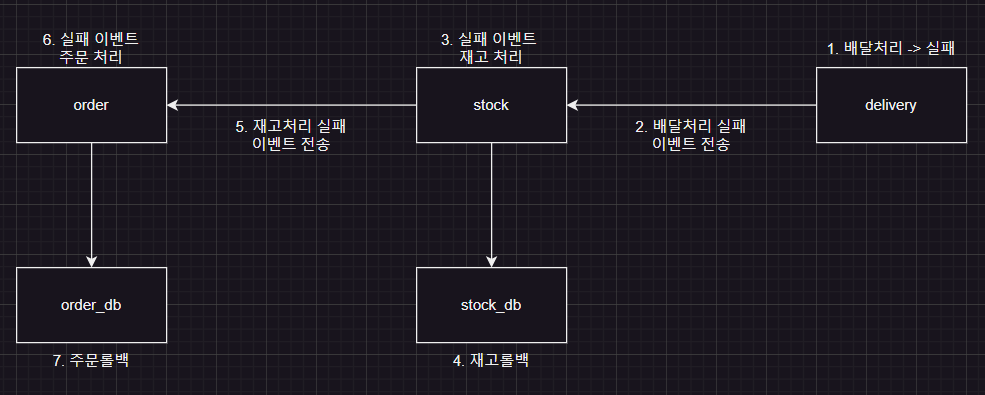
직접 구현해보자.
예제코드주소
먼저 이벤트 처리에 필요한 Kafka와 Zookeeper를 Docker 컨테이너 형태로 띄워보자.
각 이벤트에 맞는 토픽을 1:1로 만들어준다.
다음으로 각 도메인을 구현해보자.
카프카의 Producer Consumer 구조는 이렇다.
성공
OrderController -> OrderService -> StockConsumer -> StockService -> DeliveryConsumer
롤백
DeliveryService -> StockConsumer -> StockService -> OrderConsumer -> OrderService
성공 시 코드
delivery에서 확률적으로 에러가 발생
실패 시 코드