01 Jul 2024
배경
깃허브 샘플 코드
회사에서 매일 업무 시작과 종료 시에 Slack을 이용해 데일리 리포트를 작성한다.
💡 0000.00.00 (월) 금일 업무 수행할 계획 [근무지: xxx오피스]
[Jira 티켓] [BE] 테스트 코드 작성 estimated 1h / left 1h
💡 0000.00.00 (월) 금일 업무 수행한 내용 [근무지: xxx오피스]
[Jira 티켓] [BE] 테스트 코드 작성 estimated 1h / left 1h / progress 1h –> left 0h [done]
업무의 시작과 종료에 어떤 업무를 해야 하고 얼마나 진행했는지 파악하기는 좋지만, 불편한 점이 몇 가지가 있었다.
- 날짜, 요일, Jira 티켓 넘버 등 오타 발생
- 아무래도 수기로 작성하다 보니 잘못된 날짜나 요일로 작성하거나 Jira 티켓 넘버가 맞지 않는 오류가 있어서 나중에 발견하고 수정하는 경우가 종종 있었다.
- 데일리 리포트 작성 자체를 잊어버리는 경우가 발생
- 보통의 경우라면 까먹지 않지만, 아침에 출근하자마자 이슈가 생겨서 회의를 하거나, 버그 발생으로 정신 없는 상태라면 잊어버리는 경우가 생겼다.
- Jira에 있는 정보를 작성할 필요가 있을까?
- 데일리 리포트는 말하자만 직접 작성하는 Jira 티켓이다. Jira에 똑같은 내용을 확인할 수 있는데 굳이 Slack 채널에 메시지를 작성해야 하는지와 같은 필요성에 의문이 들었다.
이러한 문제점들이 있어서 데일리 리포트를 자동화해주는 서버를 만들어 효율을 높이려 시도했다.
먼저 구현 흐름은 이렇게 잡았다.
- Jira API를 이용해서 원하는 이슈 정보 불러온다.
- 데일리 리포트에 [진행 중]인 이슈와 오늘 완료한 [완료됨]의 이슈의 정보가 필요함
- 불러온 이슈를 서버에서 가공
- 회사에서 사용하는 데일리 리포트 양식이 있었기 때문에 해당 양식으로 출력해야 하기 때문에 가공하는 작업이 필요하다.
- 이슈의 추정 시간, 소요 시간 등은 가져올 수 있지만 진행한 시간은 계산을 해야 했기 때문에 해당 로직도 필요하다.
- 평일 (월 ~ 금) 업무 시작 시간인 오전 09시와 업무 종료 시간인 오후 06시에 @Scheduler를 사용하여 자동으로 Slack으로 메시지를 보낸다.
프로젝트 생성
Jira API 연동을 위해 openfeign 의존성을 추가해주고 scheduler batch job을 위해 spring batch를 추가해준다.
Slack Message를 이용하기 위해 Slack 의존성도 추가해준다.
Jira에서 이슈 정보를 가져오기
먼저 @EnableScheduling, @EnableFeignClients 를 추가해서 scheduler와 feign client를 활성화 해준다.
Feign client를 이용하여 Jira api에 issue 정보를 요청한다.
여기서 jql은 Jira Query Language이다. Jira Issue 를 검색하기 위한 구조적인 언어이다.
Jira API에서 받아온 정보를 가공하여 Slack으로 전송한다.
Slack에서는 메시지를 Block Template를 이용하여 작성할 수 있다.
Slack Block Builder
Slack API를 이용하여 Blocks를 이용하여 원하는 템플릿을 만들고 chatPostMessage를 이용하여 메시지를 보낸다.
스케줄러를 사용하여 일정한 시간에 Slack Message 전송
결과
성공적으로 메시지가 나오는 모습을 보인다.

27 Jun 2024
동시성 이슈란?
동시성 이슈는 여러 스레드가 동시에 공유 자원에 접근하거나 수정할 때 발생할 수 있는 문제입니다.
데이터 불일치, 프로그램 충돌, 비정상적인 동작 등이 발생할 수 있기 때문에 유의하고 코드를 작성해야 한다.
해당 내용을 예제코드로 알아보자.
예제 코드 레포지토리 주소
동시성 이슈 발생
먼저 계좌에서 출금을 하는 동작으로 동시성 이슈가 발생하는 경우를 알아보자.
100개의 요청이 들어오는 경우 100개가 빠져서 0을 기대하지만 실제 잔고는 기대와는 다르게 출력된다.
이러한 동시성 이슈를 해결하는 방법을 알아보자.
synchronized
자바에서 synchronized 키워드는 멀티스레드 환경에서 동시성 문제를 해결하기 위해 사용한다.
이 키워드는 특정 코드 블록에 대해 한 번에 하나의 스레드만 접근하도록 보장하여, 여러 스레드가 동시에 해당 코드에 접근할 때 발생할 수 있는 데이터 충돌이나 일관성 문제를 방지한다.
synchronized 키워드를 메서드에 적용하면 해당 메서드를 호출할 때, 객체나 클래스(정적 메서드)에 대한 락을 걸어서 다른 스레드가 해당 메서드를 동시에 실행하지 못하게 한다.
코드 블록에 적용하면, 그 코드 블록에만 락을 걸어 다른 스레드가 동시에 접근하는 것을 방지한다.
내장 클래스
자바 내장 Lock 인터페이스와 스프링 내장 인터페이스 LockRegistry를 활용하는 방법으로도 동시성 이슈를 해결할 수 있다.
Lock은 java.util.concurrent.locks 패키지에 포함되어 있으며, ReentrantLock이 대표적인 구현 클래스입니다.
Lock 객체는 명시적으로 lock()과 unlock() 메서드를 호출하여 락을 얻고 해제할 수 있다.
tryLock() 메서드는 대기 시작을 제한하거나, 특정 조건에서 비차단식으로 락을 시도할 수 있다.
Lock은 interrupt()를 호출한 경우, 락을 얻지 못했을 때 스레드를 종료할 수 있다.
Spring에서는 LockRegistry를 제공한다. 가장 흔히 사용하는 구현체는 DefaultLockRegistry다.
이 클래스는 로컬 락이나 분산 락을 제공할 수 있다.
Lock과 마찬가지로 명시적으로 락을 획득하고 해제할 수 있고 executeLocked 메서드를 사용하면 지정된 자원에 대해 락을 획득하고, 락을 해제하는 과정까지 자동으로 관리한다.
낙관적 락
낙관적 락은 데이터 충돌이 자주 발생하지 않을 것이라고 가정하고, 락을 미리 걸지 않고 작업을 먼저 시도하고 나서 충돌이 발생했을 때 처리하는 방식이다.
즉, 작업을 수행하기 전에 락을 걸지 않고, 충돌이 발생할 때만 오류를 발생시켜 해결하는 방식이다.
낙관적 락의 장점은 락을 사용하지 않기 때문에 성능 저하가 적고, 높은 동시성 환경에서도 효율적으로 동작한다.
하지만 충돌이 발생할 경우 롤백이 필요하며, 데이터 충돌이 높을 경우 오히려 성능에 좋지 않다.
사용 방법은 데이터나 엔티티에 버전 정보를 추가하여, 사용자가 데이터를 수정할 때 버전 번호를 체크하는 방식으로 구현한다.
Spring Data JPA에서 @Lock(LockModeType.OPTIMISTIC_WRITE)로 설정할 수 있다.
비관적 락
비관적 락은 낙관적 락과 반대로 데이터 충돌이 발생할 가능성이 높다고 가정하고, 충돌이 발생하기 전에 데이터를 잠가 버리는 방식이다.
즉, 락을 먼저 걸고 작업을 수행해서 데이터 충돌을 완전히 방지하려는 접근이다.
비관적 락의 장점은 데이터 충돌을 완전히 방지한다는 점이다. 하지만 단점으로는 락을 걸고 해제하는 과정에서 대기 시간이 발생하여 성능이 저하될 수 있다.
또한 높은 동시성 환경에서는 병목 현상이 발생할 수 있다.
사용법은 DB에서 SELECT FOR UPDATE와 같은 SQL 명령을 사용하여 데이터베이스에서 레코드를 수정할 때 락을 걸어 다른 트랜잭션이 해당 데이터를 수정하지 못하도록 한다.
Spring Data JPA에서 @Lock(LockModeType.PESSIMISTICE_WRITE)로 설정할 수도 있다.
Named Lock
Named Lock은 데이터베이스에서 특정 리소스를 잠그는 데 사용된다.
데이터베이스의 SELECT FOR UPDATE와 유사한 기능을 제공하지만, 이름을 기반으로 잠금을 걸 수 있어, 더 유연한 방식으로 잠금을 관리할 수 있다.
@Query 애너테이션을 사용하여 명시적인 Named Lock을 설정할 수 있다.
MySQL의 GET_LOCK 함수를 이용하여 이름 기반 잠금을 설정할 수 있다.
Redis Lettuce 분산 락
Redis Lettuce 분산 락은 Redis를 사용해서 구현한다.
Redis는 기본적으로 단일 스레드로 동작하기 때문에, 분산 환경에서 여러 애플리케이션 인스턴스가 동시에 같은 자원에 접근할 때 Lettuce 클라이언트를 통해 분산 락을 구현할 수 있다.
Lettuce는 Java에서 Redis와의 연결을 제공하는 비동기 Redis 클라이언트이다.
Lettuce 클라이언트를 사용하여 분산락을 구현할 때는, 주로 SET 명령을 사용해 락을 설정하고 일정 시간 후 자동으로 해제되는 방식으로 동작한다.
SETNX(Set if Not Exists) 명령을 사용해 분산 락을 구현할 수 있다.
Redis Redisson 분산 락
Redisson은 Redis를 위한 고급 클라이언트로, 분산 시스템을 구축할 때 유용한 기능들을 제공한다.
Redis의 기본적인 SETNX 방식보다 더 높은 수준의 추상화를 제공하며, 분산 환경에서 락을 쉽게 구현할 수 있도록 도와준다.
Redisson은 ReentrantLock을 사용하여 락을 구현한다.
Redisson은 Redis의 잠금을 기본적으로 비동기 방식으로 처리하고, Java의 ReentrantLock과 유사한 방식으로 동작한다.
Redisson 분산 락은 하나의 락을 여러 노드에서 공유할 수 있게 해준다.
특징으로는 락을 설정할 때 타임아웃을 지정할 수 있으며, 동일한 스레드가 이미 획득한 락을 재진입할 수 있다.
또한 락의 유효성을 지속적으로 검사하고, 잘못된 락을 자동으로 해제한다.
24 Jun 2024
회사에서 레거시 API를 RESTful하게 전환하는 과정을 정리해보자.
REST API?, RESTful?
먼저 REST, REST API, RESTful 용어를 정리해보자.
REST(Representational State Transfer)
REST는 웹 서비스 아키텍처 스타일의 하나로, 시스템 간의 상호작용을 간단하고 효율적으로 만들기 위한 원칙을 정의한다.
REST는 웹에서 자원을 처리하는 방식으로 네트워크 상의 시스템들이 상호작용하는 방법에 대한 규칙을 제공한다.
REST는 약자로 자원을 이름으로 구분하여 자원의 상태를 주고받는 모든 것을 의미하는 것이다.
REST는 3가지의 구성 요소를 가지고 있다.
- 자원: HTTP URI를 통해 자원을 명시
- 자원에 대한 행위: HTTP Method를 이용(GET, POST 등)
- 자원에 대한 행위의 내용: URI에 대한 CRUD를 적용하는 것을 의미
REST API
REST API는 REST 아키텍처 스타일을 따르는 웹 서비스 인터페이스이다.
REST API는 클라이언트가 서버와 데이터를 교환할 때 REST의 규칙을 따른다.
즉, 자원을 HTTP 메서드로 처리하는 API다.
RESTful
RESTful은 REST 아키텍처 스타일을 따르는 웹 서비스를 의미한다.
RESTful한 시스템은 REST의 원칙을 준수하여 설계된 시스템을 말한다.
RESTful API는 상태를 서버에 저장하지 않으며, 클라이언트가 필요한 모든 정볼;ㅡㄹ 요청에 포함해야 한다.
REST API 설계 규칙
RESTful 하기 위한 REST API 설계 규칙을 알아보자.
URI는 동사보다는 명사를, 대문자보다는 소문자를 사용해야 한다.
마지막에 슬래시 (/)를 포함하지 않는다.
언더바 대신 하이폰을 사용한다.
파일확장자는 URI에 포함하지 않는다.
행위를 포함하지 않는다.
파일 확장자는 URL에 포함시키지 않는다.
전달하고자 하는 명사를 사용하되, 컨트롤 자원을 의미하는 경우 예외적으로 동사를 사용한다.
URI에 작성되는 영어를 복수형으로 작성한다.
현재 진행하고 있는 프로젝트는 이러한 규칙이 적용되어 있지 않아, RESTful 하지 못하다.
또한, 레거시 프로젝트는 API 자체로 어떠한 의미를 가지는지 파악하기 힘들고 어떤 도메인의 API인지 일관성과 규칙이 없어서 직관적으로 이해하기가 어렵다.
GET, POST만을 이용해서 API가 작성되어 있기 때문인지, 행위를 URI에 포함시켜 작성해서 URI만 보고 어떤 API인지 이해하기가 어렵다.
이런 부분들이 합쳐져서 프론트 개발자와 협업이 힘들어지는 단점이 추가된다.
어떤식으로 수정?
이것을 백엔드단에서 프론트를 고려하지 않고 혼자서 처리하게 되면, 오히려 변경사항이 많아서 협업하기에 부정적인 결과를 만들어 낼 것으로 판단했다.
그래서 프론트 개발자와 함께 조금씩 도메인 별로 API를 수정해 나가는 것을 목표로 작업을 진행했다.
먼저 URI의 이름만 바뀌는 정도라면 프론트에서도 수정하는 코드의 양이 그리 많진 않다는 피드백을 받고 도메인 별로 API를 분류했다.
흩어져있던(서로 관련이 없던) API를 각 도메인으로 모으니 기능이 겹치는 API가 있기도 했다.
또한 API를 행위에 따라서 분류하기 편해져서 API 네이밍에 큰 도움이 되었다.
다음으론 자원의 행위에 따라 API를 수정했다.
GET과 POST로만 이루어진 API들을 PATCH, DELETE 등을 이용해서 수정해서 같은 URI라도 행위에 따라서 다른 API로 만들 수 있어서 깔끔한 형태의 API가 만들어 졌다.
예를 들어, GET /api/v1/members, POST /api/v1/members 이 두가지의 행위의 코드가 PATCH, DELETE를 추가해서 네 가지의 행위를 가진 API가 되어서 좀 더 효율적인 구조가 되었다.
마지막으로 API를 수정하고 Swagger와 Postman을 이용해서 API 명세를 작성하여 제공하는 방식으로 적용을 마무리 지었다.
18 Jun 2024
문제 상황
회사에서 기능을 구현하다 프론트에서 보낸 요청 중 저장 후 저장한 객체를 조회하는 로직 부분에서 오류가 발생했다.
원인을 분석해보니 프론트 비동기 요청에서 해당 요청을 동시에 여러개를 보내서 순서가 보장되지 않는 문제를 발견했다.
해당 상황을 샘플 코드로 알아보자
예를 들어, 프론트에서 axios 요청을 진행했다고 가정해보자.
백엔드에서는 해당 요청의 내용과 쓰레드 정보를 출력한다.
요청 실행 결과를 확인해보면 해당 요청의 순서가 보장되지 않는다.
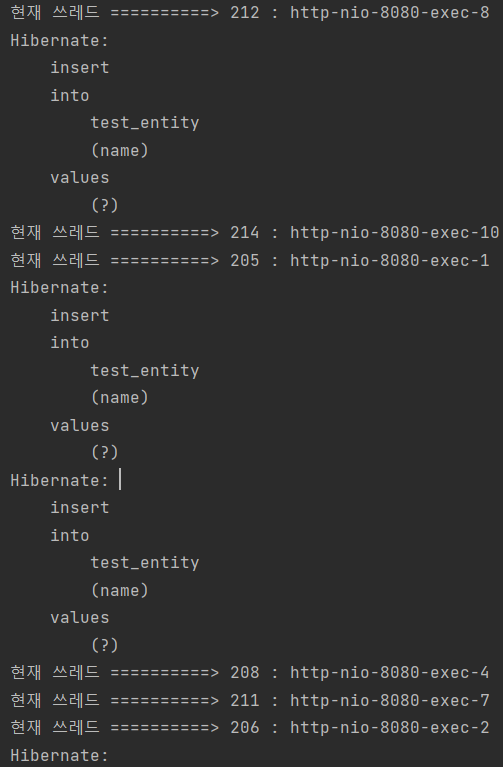
또한 DB에 저장하는 로직을 생성해서 저장되는 것을 보아도 순서가 보장되지 않는다.
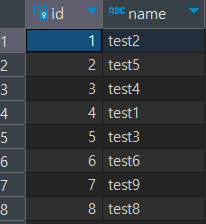
문제가 생기는 이유가 무엇일까?
이유는 답은 비동기 요청 자체에 있다. 비동기 요청은 해당 요청의 반환을 기다리지 않는다.
그래서 요청 후에 그 값이 저장되기 전에 다른 요청을 보내버리니 순서가 꼬여버린다.
그렇다면 백엔드에서 해당 문제 해결 방법은 없을까?
synchronized 키워드를 사용해서 한번에 하나씩 사용하면 순서가 보장되지 않을까?
synchronized 키워드는 한번에 하나의 요청을 처리할 뿐이지 순서를 보장해서 처리하진 않는다.
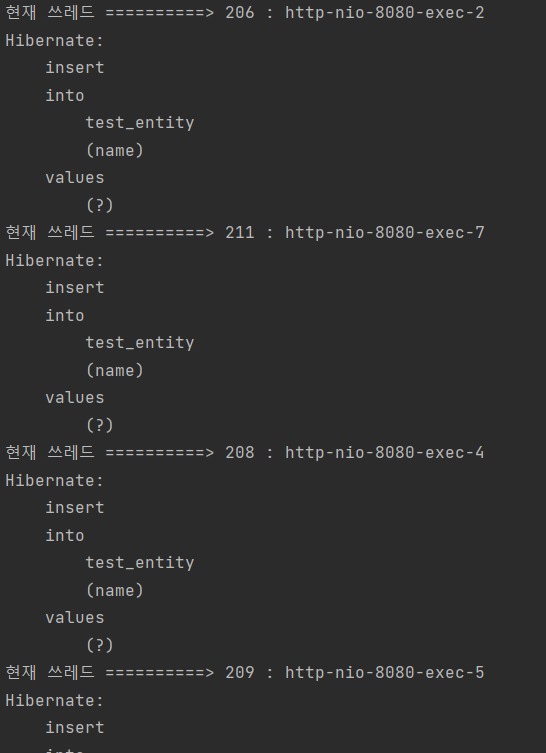
클라이언트에서 10개의 요청을 순차적으로 동시에 보내더라도, 서버에 각각의 요청이 도착하는 순서는 다를 수 있기 때문에 클라이언트 요청과 서버에서의 처리 순서가 일치하지 않을 수 있다.
클라이언트에서 요청을 보낼 때 요청의 순서를 유지할 수 있는 방법을 찾아야 한다.
해결 방법은?
요청 순서를 기억하는 메커니즘 구현
각 요청에 고유한 식별자를 붙이고, 서버에서 요청을 순서대로 처리한다.
비동기 처리 후 결과를 정렬해서 반환
모든 요청을 비동기적으로 처리한 후에 결과를 정렬해서 반환한다.
클라이언트에서 요청의 순서를 보장할 수는 있지만, 처리 시간이 오래 걸리거나 요청이 많을 경우에는 효율적이지 않다.
클라이언트에서 순차적으로 요청을 보내기
클라이언트에서 요청을 순차적으로 보내고 서버에서 순서대로 처리한다.
요청의 순서를 보장할 수는 있지만, 처리 시간이 오래 걸리는 경우 클라이언트에서 불필요하게 대기해야 한다.
클라이언트에서 async, await를 사용하여 하나의 요청이 완료되고 기다렸다가 다시 요청 보내기
결과
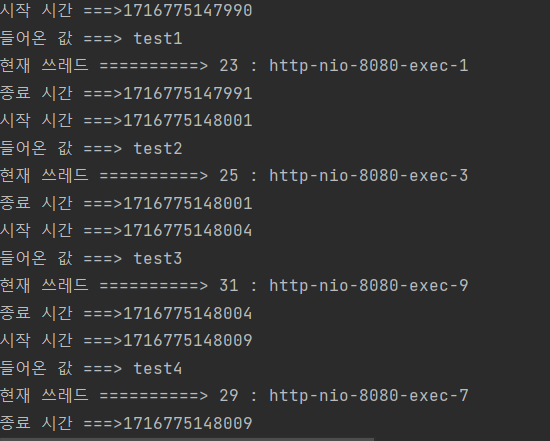
08 Jun 2024
N+1 문제란?
- ORM 기술에서 특정 객체를 대상으로 수행한 쿼리가 해당 객체가 가지고 있는 연관관계 또한 조회하게 되면서 N번의 추가적인 쿼리가 발생하는 문제를 말한다.
- 연관 관계가 설정된 엔티티를 조회할 경우에 조회된 데이터 갯수(n) 만큼 연관관계의 조회 쿼리가 추가로 발생하여 데이터를 읽어오는 현상
- 연관 관계에서 발생하는 이슈로 연관 관계가 설정된 엔티티를 조회할 경우에 조회된 데이터 갯수(n) 만큼 연관관계의 조회 쿼리가 추가로 발생하여 데이터를 읽어오게 된다.
- 즉, 1번의 쿼리를 날렸을 때 의도하지 않은 N번의 쿼리가 추가적으로 실행되는 것이다. 이를 N+1 문제라고 한다.
발생하는 이유
- N+1문제가 발생하는 근본적인 원인은 관계형 데이터베이스와 객체지향 언어간의 패러다임 차이로 인해 발생한다.
- 객체는 연관관계를 통해 레퍼런스를 가지고 있으면 언제든지 메모리 내에서 Random Access를 통해 연관 객체에 접근할 수 있지만 RDB의 경우 Select 쿼리를 통해서만 조회할 수 있기 때문이다.
- JPA Repository로 find 시 실행하는 첫 쿼리에서 하위 엔티티까지 한 번에 가져오지 않고, 하위 엔티티를 사용할 때 추가로 조회하고 JPQL은 기본적으로 글로벌 Fetch 전략을 무시하고 JPQL만 가지고 SQL을 생성하기 때문에 발생한다.
발생하는 상황
- JPA Repository를 활용해 인터페이스 메소드를 호출할 때(Read 시)
- 1:N 또는 N:1 관계를 가진 엔티티를 조회할 때 발생
- JPA Fetch 전략이 EAGER 전략으로 데이터를 조회하는 경우
- JPA Fetch 전략이 LAZY 전략으로 데이터를 가져온 이후에 연관 관계인 하위 엔티티를 다시 조회하는 경우
- 즉시로딩인 경우
- JPQL에서 만든 SQL을 통해 데이터를 조회
- 이후 JPA에서 Fetch 전략을 가지고 해당 데이터의 연관 관계인 하위 엔티티들을 추가 조회
- 2번 과정으로 N + 1 문제 발생
- LAZY(지연 로딩)인 경우
- JPQL에서 만든 SQL을 통해 데이터를 조회
- JPA에서 Fetch 전략을 가지지만, 지연 로딩이기 때문에 추가 조회는 하지 않음
- 하지만, 하위 엔티티를 가지고 작업하게 되면 추가 조회가 발생하기 때문에 결국 N + 1 문제 발생
Sample Code
먼저 Member와 Team 엔티티를 생성하자
문제 상황을 확인하기 위해 setup으로 Team 10개, Member 10개를 저장하고 결과를 조회해보자.
-> 원하는 결과는 쿼리 1번인데 team에 해당하는 member에 대한 쿼리 10번이 추가로 나간다.
이러한 문제를 Fetch.MODE를 Eager에서 Lazy로 바꾸면 해결되는지 알아보자.
Lazy로 바꾸어도 해결되지 않는 모습을 볼 수 있다.
해결방법
그렇다면 N+1 문제를 어떻게 해결할 수 있을까?
방법은 4가지 정도가 있다.
- Fetch Join
- Entity Graph Annotation
- Subselect
- Batch Size
Fetch Join
JPA Fetch Join을 사용하면 부모와 자식 관계의 엔티티를 한 번에 조회하므로 N+1 문제를 해결할 수 있다.
EntityGraph Annotation
EntityGraph는 JPA에서 특정 엔티티의 연관된 속성들을 미리 로딩할 수 있게 도와주는 기능이다.
이 방식은 쿼리 메서드에서 연관된 엔티티를 명시적으로 지정하여 Lazy Loading을 사용하더라도 필요한 연관 엔티티를 한 번에 로드할 수 있다.
FetchMode.SUBSELECT
FetchMode.SUBSELECT는 서브쿼리 방식으로 연관된 엔티티들을 조회한다.
연관된 자식 엔티티들을 SELECT 쿼리로 여러 번 조회하지 않고, 부모 엔티티에 대한 조회가 끝난 후, 추가적인 서브쿼리를 한 번 실행하여 자식 엔티티들을 모두 가져온다.
Batch Size
Batch Size는 여러 개의 엔티티를 한 번에 배치 처리하는 방법이다.
Batch Size를 설정하면, Lazy Loading 방식으로 연관된 엔티티들을 N개씩 묶어서 한 번의 쿼리로 가져오게 된다.
Batch Size를 설정하는 방법은 직접 엔티티에 @BatchSize 어노테이션으로 적용하는 방법이 있고, application.yml 파일에 적용하는 방법이 있다.